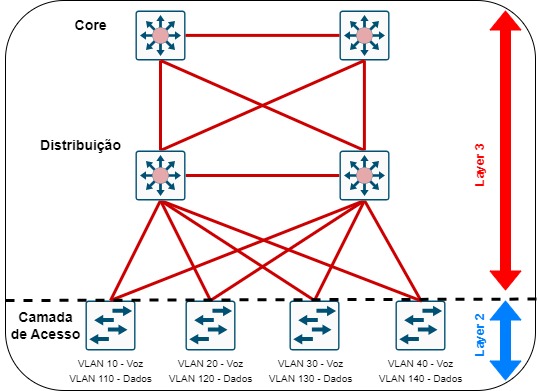
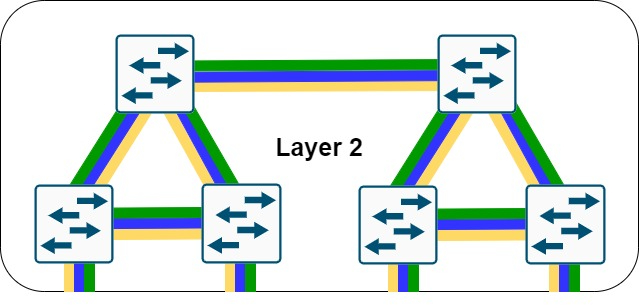
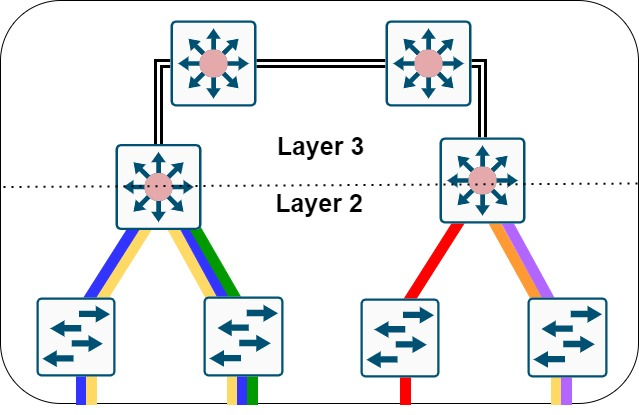
A evolução das redes wireless trouxe consigo uma crescente demanda por escalabilidade, flexibilidade e automação. Em ambientes corporativos com dezenas, centenas ou até milhares de Access Points (APs), a atribuição manual de configurações pode se tornar impraticável. É nesse cenário que o recurso AP Filter se destaca nas controladoras Cisco Catalyst 9800, permitindo uma configuração automatizada, inteligente e baseada em regras de correspondência usando expressões regulares (regex).
O que é o AP Filter?
O AP Filter é um mecanismo que permite atribuir automaticamente as três principais tags da arquitetura baseada em tags da Catalyst 9800:
Policy Tag
Site Tag
RF Tag
Essas tags controlam como o AP atua, quais políticas são aplicadas e como o rádio é configurado. Com o AP Filter, essas associações são feitas com base em regras de correspondência com nomes de AP, sem necessidade de intervenção manual por AP.finidos pelo administrador, sem necessidade de intervenção manual por AP.
Como funciona
O mecanismo avalia o nome do AP no momento em que ele se registra na controladora (Join) e verifica se existe alguma regra de AP Filter configurada. Caso exista, a controladora aplica a combinação de tags definida na regra.
Caso nenhuma regra seja satisfeita, o sistema aplica as tags definidas como default.
Condições de Correspondência (Match Conditions)
As regras usam expressões regulares (regex) aplicadas ao nome do AP (AP Name) como base de correspondência.
Você pode usar expressões como:
^RJ-.* → corresponde a qualquer nome de AP que começa com “RJ-“
.*C9136.* → corresponde a nomes que contenham “C9136”
.*-HOSP-[0-9]{2}$ → corresponde a nomes terminando em “-HOSP-01”, “-HOSP-99”, etc.
Essas condições são altamente úteis para aplicar políticas por região, por modelo de AP, ou por qualquer outro critério lógico de agrupamento.gião, por modelo de AP, ou por qualquer outro critério lógico de agrupamento.
Estrutura de uma Regra
Cada regra de AP Filter possui:
Expressão regular (Regex)
Associação de Tags (Policy Tag, Site Tag e RF Tag)
Prioridade (ordem na lista de filtros, de cima para baixo)
A ordem de avaliação respeita a ordem das regras na lista: a primeira correspondência válida é aplicada.
Configuração via GUI
A interface gráfica da controladora Catalyst 9800 facilita a configuração dos AP Filters:
Vamos imaginar o seguinte cenário: você tem APs em diferentes cidades do Brasil. Para automatizar o comportamento esperado, você cria filtros como:
Regex Match Condition
Policy Tag
Site Tag
RF Tag
^SP-.*
pt_sp
st_sp
rf_sp
^RJ-.*
pt_rj
st_rj
rf_rj
.* (padrão genérico)
pt_default
st_default
rf_default
Resultado: assim que o AP “SP-AP01” se registra, a controladora automaticamente associa as tags da primeira regra com correspondência.
Exemplos com Expressões Regulares (Regex)
A AP Filter suporta regex como método avançado de correspondência, permitindo maior controle em ambientes com regras complexas de nomeação. Veja alguns exemplos:
Regex Match Condition
Policy Tag
Site Tag
RF Tag
^NE-[A-Z]{2}-\d+
pt_ne
st_ne
rf_ne
.*C9130AX[E,I].*
pt_model
st_model
rf_model
.*-HOSP-[0-9]{2}$
pt_hosp
st_hosp
rf_hosp
Explicando alguns padrões:
^NE-[A-Z]{2}-\d+ → corresponde a nomes como NE-BA-01, NE-PE-10
.*C9130AX[E,I].* → corresponde a qualquer AP modelo C9130AXE ou C9130AXI
.*-HOSP-[0-9]{2}$ → identifica APs localizados em hospitais com nomes como AP-SP-HOSP-01
Dica: Teste suas expressões em ambientes de homologação antes de aplicá-las em produção.
Benefícios do uso de AP Filter
Escalabilidade: elimina a necessidade de atribuição manual em ambientes grandes
Agilidade: APs entram na rede já com as configurações corretas
Padronização: garante consistência por localização, modelo ou outro critério
Automação: facilita integração com processos de PnP (Plug and Play)
Boas práticas
Use nomenclatura de APs consistente para facilitar o uso de regex
Priorize regras específicas antes das genéricas
Sempre configure uma regra genérica como fallback
Documente suas regras para manter clareza na operação
Conclusão
O AP Filter representa um avanço significativo na automação e escalabilidade da infraestrutura wireless com Cisco Catalyst 9800. Em vez de depender de configuração manual, a controladora toma decisões inteligentes com base em expressões regulares definidas pelo administrador. Isso resulta em uma gestão mais eficiente, menos propensa a erros e alinhada com as melhores práticas de redes corporativas modernas.
Com o uso inteligente do AP Filter, sua rede wireless está pronta para crescer de forma organizada, segura e automatizada.
O sucesso de uma rede wireless corporativa está diretamente ligado à qualidade do sinal, estabilidade de conexão e capacidade de resposta às condições variáveis do ambiente. Com centenas de dispositivos conectados, movimentação constante de pessoas, fontes de interferência e diferentes padrões de construção, manter o espectro limpo e bem ajustado é um desafio.
Para isso, a Cisco oferece o RRM (Radio Resource Management), um conjunto de funcionalidades integradas nas controladoras Catalyst 9800 que automatizam e otimizam a gestão do ambiente de RF, reduzindo falhas humanas e melhorando significativamente a experiência dos usuários.
O que é RRM?
O RRM é um mecanismo de gestão automatizada de recursos de rádio, que permite que a controladora monitore e ajuste dinamicamente os parâmetros de RF dos Access Points:
Potência de transmissão (TPC)
Atribuição de canais (DCA)
Plano de cobertura e interferência
Parâmetros de roaming e sensibilidade
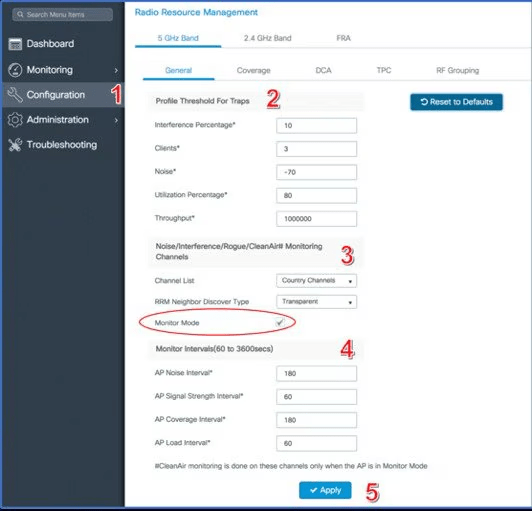
Na plataforma Catalyst 9800, o RRM é parte nativa do sistema IOS-XE e oferece tanto configurações manuais quanto automáticas, com opções de agendamento e ajustes sensíveis por banda e perfil de RF.
Componentes do RRM
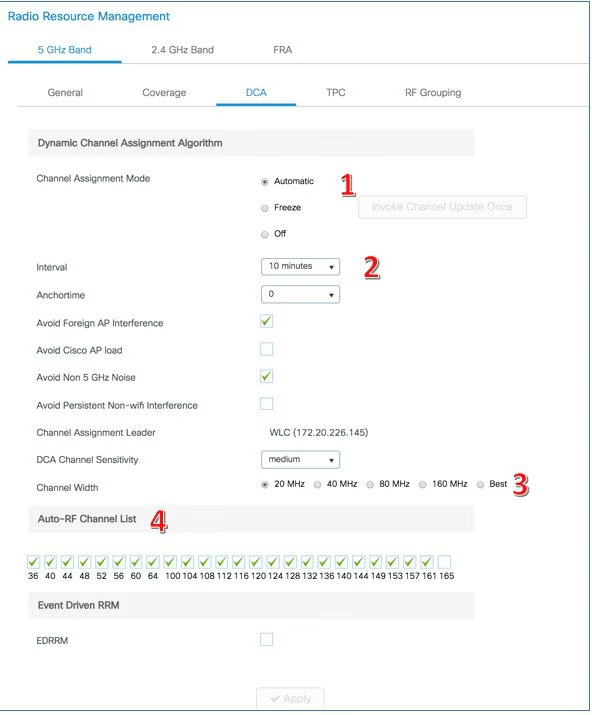
1. DCA (Dynamic Channel Assignment)
Responsável por selecionar dinamicamente os melhores canais para os APs, evitando interferências co-channel (CCI) e adjacent-channel (ACI). O algoritmo considera:
Uso do canal
Interferência detectada
Clientes conectados
Eventos de espectro
Configurações comuns:
Largura de canal (20, 40, 80 MHz)
Exclusão de canais DFS
Intervalo de reavaliação
Horário de atualização (Anchor Time)
Modos de operação DCA:
Automatic: DCA realiza análises e alterações de canal dinamicamente.
Freeze: DCA continua analisando o ambiente, mas não altera os canais automaticamente.
Off: DCA é totalmente desativado.
A figura abaixo apresenta os seguinte componentes:
Choose DCA operational mode (Automatic)
DCA Monitoring metrics
Choose Global Bandwidth
Select DCA operating channels
Dynamic Channel Assignment
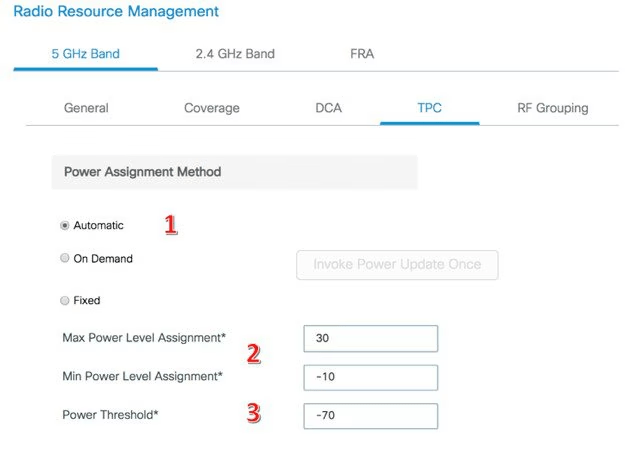
2. TPC (Transmit Power Control)
Ajusta automaticamente a potência de transmissão dos APs, equilibrando cobertura e interferência. Reduzir a potência evita sobreposição excessiva de células.
Configurações:
TPC Mode: Automatic, On Demand ou Fixed
Potência máxima e mínima permitidas
TPC Threshold (em dBm)
Transmit Power Control
3. Coverage Hole Detection and Mitigation (CHDM)
Detecta áreas com cobertura deficiente, com base no RSSI dos clientes, e permite que a controladora aumente temporariamente a potência dos APs vizinhos.
Parâmetros: número de clientes afetados, porcentagem de pacotes perdidos, nível de RSSI
Pode ser usado com TPC e DCA para correção automática
4. Client Load Balancing
Distribui os clientes entre APs ou entre bandas (2.4 GHz / 5 GHz / 6 GHz), evitando sobrecarga de um único ponto de acesso.
Controlado por: Client Window Size, Maximum Denial Count
Pode ser configurado com Band Select
Importante:
Client Window Size define o número de clientes de comparação entre APs vizinhos
Maximum Denial Count limita a quantidade de vezes que um cliente pode ser redirecionado
5. Rx-SOP (Receive Start of Packet)
Define o nível de sensibilidade do AP para processar pacotes. Um Rx-SOP mais agressivo ignora sinais fracos, reduzindo interferência de APs distantes, mas pode afetar roaming.
Exemplo prático:
Ambientes de alta densidade (auditórios, eventos): usar Rx-SOP mais agressivo
Ambientes de baixa densidade: usar Rx-SOP mais permissivo
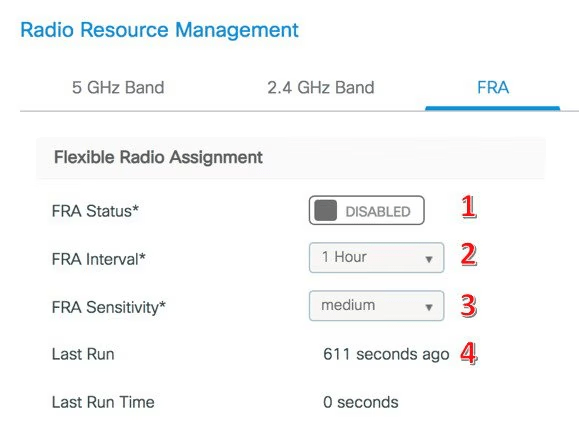
FRA (Flexible Radio Assignment)
O Flexible Radio Assignment (FRA) permite que rádios flexíveis dos APs modernos (como as séries 2800, 3800, 9100) operem em diferentes modos, dinamicamente, de acordo com a densidade e as condições do ambiente.
Modos disponíveis para um rádio FRA:
Modo
Descrição
2.4 GHz
Rádio opera normalmente na banda de 2.4 GHz
5 GHz
Rádio é convertido para operar como 5 GHz adicional (Dual 5 GHz mode)
Monitor
Rádio é usado para monitoramento passivo, WIPS, CleanAir, etc.
Security Monitor
Usado para detecção de ameaças, rogue APs e interferência
Wireless Sniffer
Modo de captura de pacotes para análise (usado com ferramentas como Wireshark)
Spectrum Analyzer
Rádio funciona como analisador de espectro (exige licença CleanAir)
Como o FRA atua com o RRM:
Quando habilitado, o FRA trabalha em conjunto com o RRM, especialmente com:
DCA (Dynamic Channel Assignment): para decidir se a densidade de APs em uma área justifica converter um rádio de 2.4 GHz para 5 GHz
TPC (Transmit Power Control): para equilibrar a cobertura após a mudança de banda
Load Balancing: pois a adição de rádios 5 GHz alivia a carga nos canais existentes
Quando usar:
Locais com alta densidade de dispositivos
Ambientes com interferência significativa em 2.4 GHz
Situações onde se deseja capacidade extra sem adicionar novos APs
Configuração:
Via GUI: Configuration > Wireless > Advanced > Flexible Radio Assignment
FRA Tab
Grupos de RRM (RF Profiles e RRM Groups)
Com a controladora 9800, é possível aplicar diferentes comportamentos de RRM a grupos de APs, usando:
RF Profiles: aplicados a bandas (2.4/5/6 GHz), definem parâmetros de RF por WLAN/SSID
RRM Groups: agrupam APs para formar domínios de decisão local para TPC e DCA
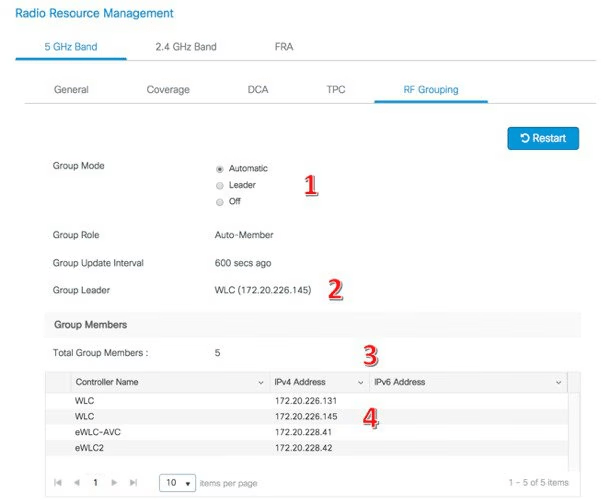
Como os APs descobrem seus vizinhos?
Através do Neighbor Discovery Protocol (NDP), os APs enviam mensagens periódicas para mapear quem está ao redor.
As mensagens vizinhas são enviadas para um endereço Multicast especial de 01:0B:85:00:00:00 e são feitas da seguinte forma:
Na Maior Potência permitida para o Canal/Banda
Na Menor Taxa de Dados suportada na banda
Com base nesses dados, o RF Group Leader coleta informações para tomar decisões de RRM.
Eleição do RF Group Leader:
Baseada no número de APs e na carga de trabalho
Pode ser forçada via configuração CLI
Exemplo: Em um campus com prédios isolados, cada prédio pode ter seu próprio RRM Group para evitar que eventos de RF em um bloco influenciem outro.
RF Grouping Tab
AI-Enhanced RRM
A partir do IOS-XE 17.9, a Cisco introduz o AI-Enhanced RRM, que usa inteligência artificial para analisar padrões de uso, interferência e comportamento dos clientes, aplicando ajustes proativos de RF.
Funcionalidades:
Sugestões de troca de canal e potência
Detecção de anomalias de cobertura
Acompanhamento de impacto nas sessões de cliente
Requer integração com o Cisco Catalyst Center para visualização completa e recomendações baseadas em IA.
Interface Gráfica (GUI) do RRM
A Catalyst 9800 permite controlar todos os aspectos do RRM via GUI. Os principais menus incluem:
Configuration > Wireless > RRM > General
Configuration > Tags > RF Tag
Configuration > Wireless > Advanced > Client Distribution
Não misture APs com RF Profiles distintos no mesmo RRM Group
Evite canais DFS em ambientes críticos (voip, videoconferência)
Mantenha o firmware atualizado para obter melhorias no algoritmo de RRM
Em ambientes sensíveis, considere usar “Freeze Mode” após otimização inicial
Exemplo de CLI útil:
show ap auto-rf 802.11a | include Channel|Tx|
config 802.11a channel global 36
config 802.11a tx-power global 5
Considerações Finais
O RRM é um dos grandes diferenciais da controladora Catalyst 9800. Com ele, a rede Wi-Fi torna-se dinâmica, adaptável e resiliente às variações do ambiente. Quando bem configurado, o RRM reduz o trabalho operacional, evita quedas de desempenho e melhora o roaming e a distribuição de carga.
Para obter o máximo do RRM:
Realize um bom RF Design inicial
Crie RRM Groups lógicos
Ajuste o Rx-SOP com base na densidade
Use AI-Enhanced RRM para ambientes dinâmicos (Requer o Catalyst Center)
Acompanhe os eventos via GUI e Catalyst Center
Com essas boas práticas, sua rede sem fio estará pronta para oferecer a melhor experiência possível aos usuários.
Links uteis
Caso deseje entender mais sobre esse assunto, deixo aqui alguns links de materiais ricos em conteúdo que poderão ajudá-lo.
A controladora Cisco Catalyst 9800 trouxe uma abordagem moderna e modular para a configuração de redes sem fio, substituindo conceitos antigos como AP Groups e FlexConnect Groups por um modelo baseado em Tags.
Neste artigo, vamos entender os três tipos principais de tags usados na C9800: Policy Tag, Site Tag e RF Tag, e como eles trabalham juntos para definir o comportamento dos Access Points (APs).
Mas antes de falarmos sobre as Tags, vamos primeiro entender como funciona o WNCd (Wireless Network Control daemon).
WNCd: O Cérebro da Controladora Wireless Cisco Catalyst 9800
A controladora Cisco Catalyst 9800 marca uma evolução importante na arquitetura de redes sem fio corporativas, baseada no sistema IOS-XE. Por trás de toda a inteligência e automação dessa plataforma está um processo central chamado WNCd — o daemon responsável por todo o plano de controle (Control Plane) da infraestrutura wireless.
WNCd e a Evolução da Arquitetura Wireless: Do IOS Monolítico ao IOS-XE Modular
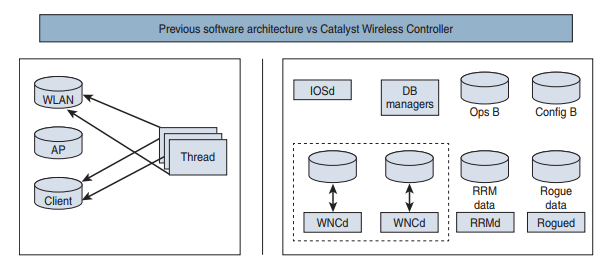
Antes de entender o papel do WNCd, é essencial compreender a mudança de paradigma que a Cisco promoveu com o lançamento das controladoras Catalyst 9800. Essas plataformas abandonaram a arquitetura monolítica do IOS tradicional e adotaram um modelo modular baseado em processos, fornecido pelo IOS-XE.
IOS tradicional: arquitetura monolítica
Nas controladoras AireOS (e até mesmo em switches com IOS clássico), o sistema operacional era composto por um único processo contínuo que executava todas as tarefas:
Processamento de pacotes
Gerenciamento de APs e clientes
Controle de rádio
Políticas de segurança e mobilidade
Limitações:
Sem isolamento de processos: falha em uma função podia afetar todo o sistema.
Difícil escalabilidade e paralelismo.
Baixa visibilidade e controle de recursos (CPU/RAM por função).
IOS-XE: arquitetura modular por processos
Com o IOS-XE, adotado pela série Catalyst 9800, o sistema se comporta como um chassis virtual de processos independentes, cada um responsável por uma função específica:
wncd: controle wireless (o foco deste artigo)
ap_election_mgr: eleição de APs
snmpd, telemetryd, bfd, ospfd: gerenciamento e roteamento
dhcpd, aaa, etc.: serviços de rede
Cada processo pode ser monitorado, reiniciado e depurado individualmente — sem causar impacto no restante do sistema.
A figura abaixo exemplifica esses dois modelos de sistema operacional.
A antiga arquitetura à esquerda (IOS) comparada com a arquitetura Catalyst Wireless à direita (IOS-XE)
Onde entra o WNCd?
Dentro dessa nova arquitetura modular, o WNCd (Wireless Network Control daemon) é o processo dedicado ao gerenciamento do plano de controle wireless, ou seja:
Responsabilidade
Exemplo de ação
Controle de clientes
Associação, roaming, timeout
Gerenciamento de APs
Join, keepalive, push de tags
Aplicação de políticas
VLANs, ACLs, roles, timers
Comunicação com rádios
Canal, potência, RRM, DFS
Interface com outros processos
AAA, syslog, telemetry
O WNCd pode operar em múltiplas instâncias paralelas (wncd_0, wncd_1, etc.), balanceando a carga por rádio/banda ou quantidade de APs.
O que é o WNCd?
WNCd (Wireless Network Control daemon) é um processo interno do sistema IOS-XE que atua como o cérebro de todas as operações wireless na controladora Catalyst 9800.
O WNCd opera em múltiplas instâncias (wncd_0, wncd_1, etc.), permitindo paralelismo e escalabilidade, especialmente em controladoras com muitos APs.
Como o WNCd se relaciona com os APs?
Quando um AP se registra via CAPWAP, o WNCd é quem:
Autentica o AP e aplica o AP Join Profile
Associa as tags (Policy, Site e RF) atribuídas a ele
Distribui as configurações wireless baseadas nessas tags
Gerencia os rádios conforme o comportamento definido nos perfis
Por que entender o WNCd é importante?
Compreender o WNCd é essencial para:
Diagnosticar problemas de clientes (ex: falhas de roaming, quedas)
Avaliar consumo de CPU/memória causados por alta densidade de APs
Compreender como as Tags são processadas e aplicadas
Monitoramento do WNCd (CLI)
# Ver status dos processos show processes platform | in wncd
# Ver logs relacionados ao WNCd show logging | include wncd
Exemplo de log WNCd
Jun 22 10:35:44.456: %WNC-4-ROAM: wncd_0: Client 00:11:22:33:44:55 roamed from AP1 to AP2
A ponte para as Tags
Agora que entendemos quem é o responsável por aplicar as políticas, fica mais fácil compreender o próximo passo: quais políticas são aplicadas e como isso é organizado.
E é aqui que entram as Tags: O WNCd aplica as configurações com base nas Tags atribuídas ao AP.
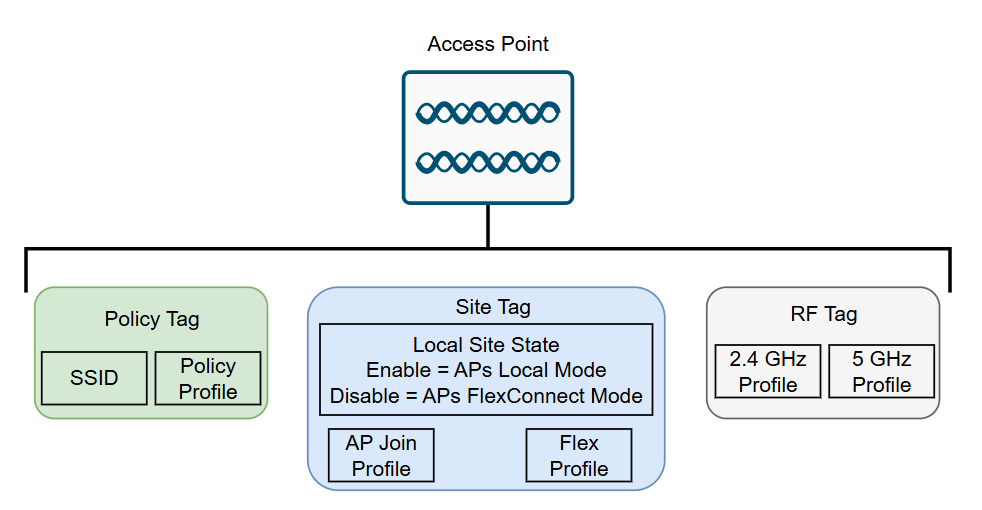
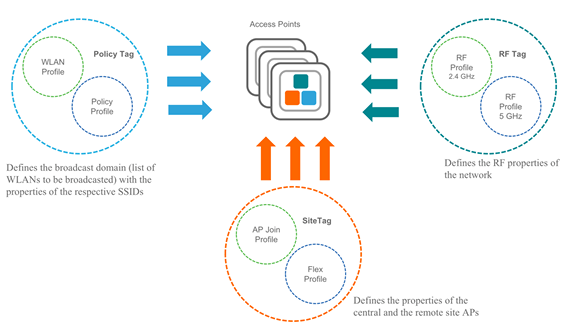
As Tags na Controladora Cisco Catalyst 9800
Com o WNCd como orquestrador da inteligência wireless, ele precisa de instruções estruturadas e reutilizáveis para aplicar as configurações de rede, rádio e controle aos APs. Essas instruções vêm na forma de Tags.
Na Catalyst 9800, três tipos de Tags são usados para definir o comportamento completo de um Access Point:
Policy Tag → O que o AP transmite e como trata os clientes
Site Tag → Como o AP se comporta e como se junta à controladora
RF Tag → Como os rádios do AP operam no espectro
Essas três Tags, quando combinadas, fornecem ao WNCd todas as informações necessárias para controlar a operação do AP.
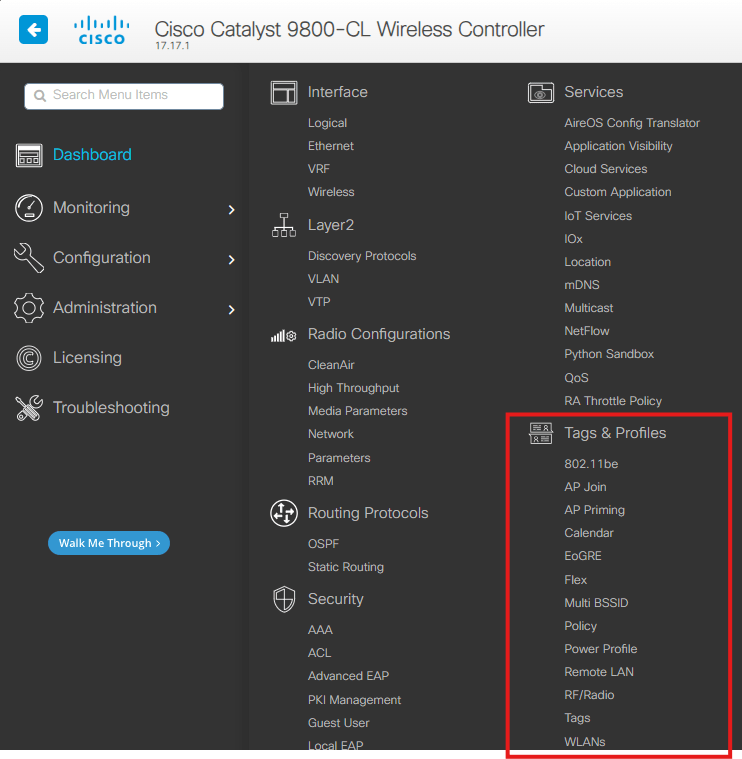
Menu Configuration > Tags and Profiles
Policy Tag – Política de Acesso
A Policy Tag define:
Quais SSIDs (WLANs) o AP irá anunciar
Quais Policy Profiles estão associados a cada SSID
Cada Policy Profile contém:
VLAN de atribuição
Método de autenticação (PSK, 802.1X, Open)
ACLs
QoS, timers de sessão
Requisição de DHCP, NetFlow, etc.
Equivalente ao antigo “AP Group” no AireOS, com muito mais granularidade.
Site Tag – Comportamento de Operação
A Site Tag define o modo de operação do AP:
Local Mode
FlexConnect
Monitor, Sniffer, etc.
Além disso, associa:
AP Join Profile: configurações de heartbeat, syslog, image download
Flex Profile: se o modo for FlexConnect
Fabric Profile: se estiver integrado ao Cisco SD-Access
Importante: só uma Site Tag pode ser atribuída por AP.
RF Tag – Comportamento de Rádio
A RF Tag é responsável por toda a configuração relacionada aos rádios do AP:
Bandas habilitadas (2.4, 5, 6 GHz)
Canal, potência e largura de banda
Thresholds (Rx-SOP, CCA, Load Balancing)
Parâmetros de RRM (DCA, TPC, CHDM)
Recursos avançados (OFDMA, MU-MIMO, BSS Coloring)
Reutilizável por grupos de APs que compartilham o mesmo perfil de cobertura.
Essa combinação é aplicada ao AP manualmente, por script ou via Cisco Catalyst Center.
CLI de verificação:
show ap tag summary show wireless tag policy summary show wireless tag site summary show wireless tag rf summary
Exemplo prático
Imagine um campus universitário com 3 prédios:
Prédio
Policy Tag
Site Tag
RF Tag
Prédio A
Policy-Corp
Site-Flex-A
RF-Standard
Prédio B
Policy-GuestOnly
Site-Monitor-B
RF-LowPower
Prédio C
Policy-Mixed
Site-Local-C
RF-HighDensity
Vantagens dessa arquitetura
Flexibilidade para automação: ideal para uso com Cisco Catalyst Center ou scripts via NETCONF/RESTCONF
Escalabilidade: reaproveite RF Tags e Policy Tags em locais diferentes
Agilidade: alterações rápidas sem reconfigurar AP a AP
Modularidade: controle por função, por prédio, por grupo
Conclusão
À medida que as redes sem fio evoluem para ambientes de alta densidade, múltiplas bandas e necessidades críticas de mobilidade, a Cisco trouxe com a Catalyst 9800 uma arquitetura moderna e escalável baseada no IOS-XE. No centro dessa arquitetura está o processo WNCd, responsável por orquestrar o controle wireless em múltiplas instâncias, garantindo resiliência, paralelismo e visibilidade operacional. Mas o WNCd, por si só, não decide como um Access Point se comporta. É aí que entram as Tags — blocos lógicos que definem, de forma modular, o que o AP anuncia (Policy Tag), como ele opera (Site Tag) e como seu rádio se comporta (RF Tag). Essa combinação entre inteligência distribuída (WNCd) e configuração segmentada (Tags) é o que permite que a Catalyst 9800 seja tão adaptável as atuais necessidades das redes modernas.
Leituras complementares
Caso deseje aprofundar os conhecimentos nesse assunto, abaixo deixo alguns materiais que podem ser utilizados como leitura complementar.
Quando falamos em segurança com o Cisco ISE (Identity Services Engine), estamos falando sobre confiança. E em um ambiente digital, a confiança é estabelecida por certificados digitais, que validam identidades e garantem comunicações criptografadas.
Neste artigo, vamos explorar por que os certificados são essenciais no Cisco ISE, quais tipos existem, como configurá-los corretamente e como evitar os erros mais comuns.
Por que o Cisco ISE depende de certificados?
O Cisco ISE é uma plataforma central de controle de acesso à rede, onde múltiplos elementos se comunicam: endpoints, switches, controladoras wireless, servidores, navegadores, AD, MDM, etc.
Para que todas essas comunicações ocorram com segurança e confiança, é necessário:
Provar a identidade das partes envolvidas (ex: o servidor ISE precisa provar que é legítimo)
Garantir que a comunicação seja confidencial (criptografia de dados)
Assegurar a integridade das mensagens (nada foi alterado no caminho)
Essas três propriedades são garantidas por certificados digitais baseados em criptografia de chave pública (PKI).
Já a figura abaixo, apresenta o processo de criptografia para cada possível processo EAP.
PEAP
EAP-TLS
EAP-TTLS
EAP-FAST
TEAP
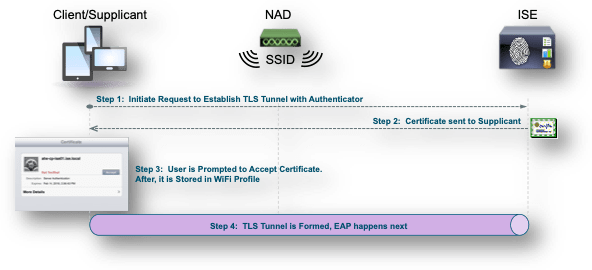
Com métodos EAP tunelados, como PEAP e FAST, o protocolo TLS (Transport Layer Security) é usado para proteger a troca de credenciais. Assim como ao acessar um site HTTPS, o cliente estabelece a conexão com o servidor, que apresenta seu certificado ao cliente. Se o cliente confiar no certificado, o túnel TLS é formado. As credenciais do cliente não são enviadas ao servidor até que esse túnel seja estabelecido, garantindo assim uma troca segura. Em uma implantação de Acesso Seguro, o cliente é um solicitante e o servidor é um nó do ISE Policy Services.
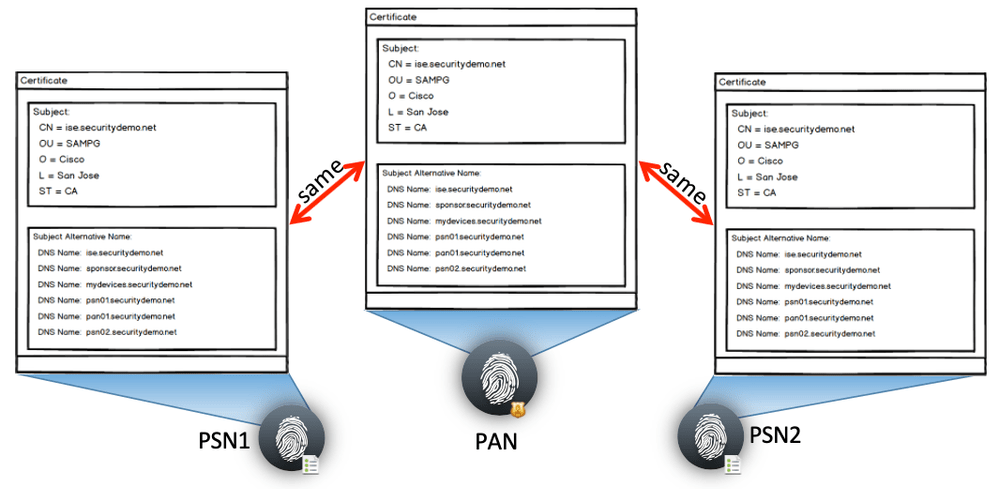
Este método utiliza o mesmo par de chaves pública e privada em todos os nós ISE. Geralmente, é usado em ambientes com muitos dispositivos do tipo BYOD. O principal motivo para seguir este modelo é garantir que o mesmo certificado seja usado em todas as PSNs; assim, os dispositivos BYOD já confiarão em qualquer servidor EAP no qual precisem se autenticar.
Para realizar este método, gere uma solicitação de assinatura de certificado (CSR) em um único nó ISE. Após vincular o certificado assinado à chave privada, exporte o par de chaves resultante e importe-o em todos os outros nós. Configure o certificado único para:
O CN do Certificado conterá um único FQDN, como ise.company.com
Autoridades Certificadoras: CA Pública x CA Interna
O certificado do ISE deve ser confiável pelo cliente — isso exige que a CA que o emitiu esteja no repositório de confiança do sistema cliente (Windows, macOS, Android, etc.).
Comparativo:
Critério
CA Pública
CA Interna
Reconhecida por padrão
✅ Sim
❌ Não (precisa importar a raiz)
Ideal para portais web
✅ Sim
⚠️ Pode gerar alerta no navegador
Ideal para EAP-TLS
✅ Sim (mas caro)
✅ Sim (usado via GPO ou MDM)
Custo
$ (certificados pagos)
Grátis, mas requer gerenciamento
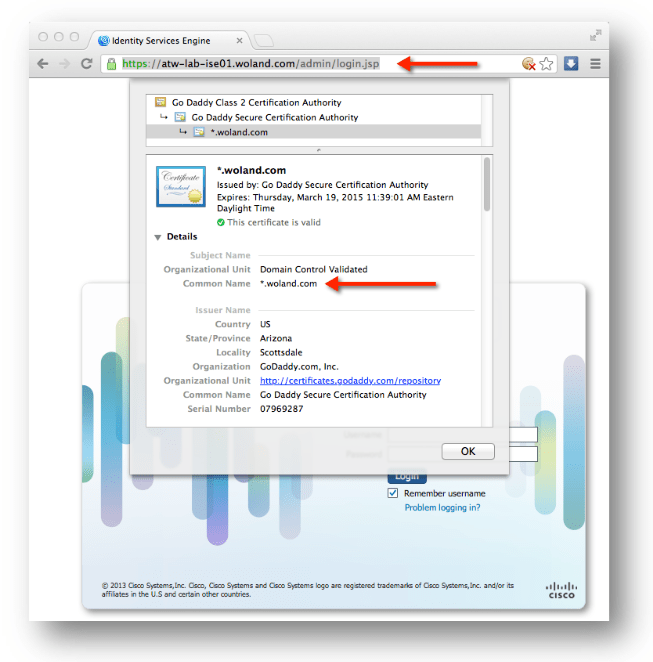
O que é um certificado wildcard?
Um certificado wildcard é um tipo de certificado digital SSL/TLS que utiliza um caractere curinga (*) no campo Common Name (CN) ou no Subject Alternative Name (SAN). Ele é utilizado para proteger múltiplos subdomínios dentro de um mesmo domínio principal.
🔹 Exemplo prático:
CN: *.empresa.com
Este certificado é válido para:
guest.empresa.com
sponsor.empresa.com
mydevices.empresa.com
ise1.empresa.com
vpn.empresa.com
Mas não é válido para:
sub.guest.empresa.com (nível adicional de subdomínio)
No Cisco ISE, os certificados wildcard são comumente usados para proteger portais web, como:
Guest Portal
BYOD Portal
Self-Service/MyDevices Portal
Portais de Sponsor
Isso porque esses portais geralmente operam em subdomínios como guest.empresa.com, sponsor.empresa.com, etc.
Vantagens:
Simplifica o gerenciamento: apenas um certificado cobre todos os portais
Reduz custos: ao invés de emitir múltiplos certificados por subdomínio
Flexibilidade: ao adicionar novos portais ou PSNs, o mesmo certificado pode ser reaproveitado
Limitações e recomendações:
EAP-TLS e certificados wildcard: Alguns clientes (como Windows e certos supplicants) podem não aceitar certificados wildcard durante a negociação EAP, especialmente em ambientes mais restritivos ou quando o nome do servidor precisa ser validado contra o CN exato.
Uso em pxGrid: pxGrid exige que o certificado tenha o nome exato do host (FQDN) no CN ou no SAN. Certificados wildcard não são recomendados para pxGrid.
Associação correta no ISE: O certificado deve ser associado ao serviço de portal web, não ao EAP ou pxGrid.
Resumo — Quando usar certificado wildcard no ISE?
Caso de uso
Wildcard é recomendado?
Portais Web (Guest, BYOD)
✅ Sim
Interface de Admin (HTTPS)
⚠️ Sim, mas com atenção
EAP (PEAP, EAP-TLS)
⚠️ Depende do supplicant
pxGrid
❌ Não recomendado
Gerenciamento de Certificados no ISE
Onde gerenciar:
Administration > System > Certificates
Você pode:
Gerar CSR para envio à CA
Importar certificados assinados (usando o CSR anterior)
Importar cadeias completas (Root + Intermediate)
Associar certificados a serviços específicos, como EAP Authentication, Admin Portal, pxGrid, etc.
Monitorar a expiração automática com alertas de renovação
Boas práticas:
Tenha um plano de renovação periódica (scriptado ou manual)
Use nomes FQDN corretos nos certificados
Certifique-se de que o campo SAN contenha o nome DNS correto
Evite reusar o mesmo certificado para múltiplos serviços (a não ser que seja wildcard)
Conclusão
O Cisco ISE é uma solução poderosa e flexível de controle de acesso à rede — mas sua segurança e funcionalidade dependem fortemente de uma infraestrutura de certificados digitais bem planejada.
Ao longo deste artigo, vimos que os certificados não são apenas um requisito técnico, mas um pilar fundamental para garantir identidade, confiança e comunicação segura entre o ISE, os dispositivos de rede, os usuários e os sistemas externos.
Seja na autenticação EAP-TLS, no acesso aos portais Guest/BYOD, na integração via pxGrid, ou na administração web — tudo passa pela confiança em certificados válidos, corretamente emitidos, distribuídos e associados.
A escolha entre um certificado por nó, por serviço ou compartilhado deve ser guiada pelo equilíbrio entre simplicidade operacional, escalabilidade e segurança. O uso de certificados wildcard pode facilitar o gerenciamento de portais web, mas deve ser feito com cuidado em cenários que envolvam autenticação EAP ou integração com pxGrid.
Caso queira entender mais a fundo sobre os certificados no ISE, recomendo a leitura do seguinte material:
Ao trabalhar com políticas no Cisco ISE, é comum utilizar atributos como grupos de usuários, SSID, tipos de dispositivos ou status de postura. Mas o que poucos administradores compreendem a fundo é de onde vêm esses atributos e como o ISE os organiza.
A resposta está nos dicionários do Cisco ISE — componentes essenciais que estruturam toda a lógica de decisão da plataforma. Neste artigo, você vai entender o que são esses dicionários, como utilizá-los e por que dominá-los torna a administração do ISE muito mais eficiente e segura.
O que são dicionários no Cisco ISE?
No Cisco ISE, um dicionário é uma coleção de atributos relacionados a uma fonte específica de dados, como o RADIUS, Active Directory, posture ou profiling. Esses dicionários são usados para criar condições em regras de autenticação, autorização, perfil de dispositivos e outras funcionalidades da plataforma.
Você pode pensar em um dicionário como uma “tabela de atributos” que o ISE consulta para entender o contexto da conexão ou a identidade do usuário/dispositivo.
Tipos de Dicionários no Cisco ISE
1. System Dictionary
Contém atributos internos do próprio ISE, como ISE Device, EndPointPolicy, AuthenticationStatus, entre outros. São amplamente usados para condições administrativas e controle interno.
2. RADIUS Dictionary
Lista atributos padrão definidos pelo protocolo RADIUS, como:
Radius:Calling-Station-ID
Radius:NAS-Port-Type
Radius:Framed-IP-Address
Esses atributos são usados frequentemente em políticas que analisam dados de portas, switches, SSIDs, entre outros.
3. Active Directory / LDAP Dictionaries
Quando o ISE se integra com um diretório externo (como o AD), ele importa um conjunto de atributos, como:
AD:MemberOf (grupo de segurança)
AD:sAMAccountName
AD:Department
LDAP:Title, LDAP:Manager
Esses atributos permitem decisões baseadas em identidade corporativa.
4. Posture and AnyConnect Dictionaries
Utilizados quando o ISE trabalha com avaliação de postura (NAC), especialmente com o agente Cisco AnyConnect. Exemplos:
Posture:Status
Cisco-AV-Pair: posture-token
ClientVersion, OS, AVCompliance
5. Profiling Dictionary
Contém atributos coletados automaticamente pelo mecanismo de profiling do ISE, como:
DeviceType
DeviceFamily
Manufacturer
OperatingSystem
Usados para identificar e classificar dispositivos conectados (impressoras, IP phones, câmeras, etc.).
6. Custom Dictionaries (Personalizados)
O administrador pode criar dicionários personalizados para suportar atributos específicos de aplicações ou extensões externas via pxGrid, scripts, APIs ou integração com firewalls.
Como os dicionários são usados nas políticas?
Os atributos presentes nos dicionários são utilizados ao criar condições dentro das Authentication ou Authorization Policies. Veja alguns exemplos práticos:
Exemplo de condição (IF)
Fonte do atributo
Radius:Calling-Station-ID = "Corp-WiFi"
RADIUS Dictionary
AD:MemberOf = "TI"
Active Directory Dictionary
Posture:Status = Compliant
Posture Dictionary
Endpoint:DeviceType = "Smartphone"
Profiling Dictionary
LDAP:Department = "Financeiro"
LDAP Dictionary
Essas condições permitem ações como: atribuir VLANs, aplicar SGTs, redirecionar para portais, bloquear acesso ou enviar CoA (Change of Authorization).
Onde visualizar e gerenciar dicionários no ISE?
Você pode acessar os dicionários e seus atributos em:
Menu: Policy > Policy Elements > Dictionaries
Nessa tela é possível:
Explorar todos os dicionários disponíveis
Ver os atributos disponíveis (nome, tipo, permissões)
Adicionar dicionários personalizados
Mapear novos atributos de um AD/LDAP
Importante: Nem todos os atributos são editáveis. A maioria dos dicionários padrão é de leitura apenas, mas os personalizados permitem configuração total.
Exemplos práticos
1. Usando um dicionário AD em uma regra
Objetivo: aplicar uma VLAN específica para usuários cujo campo Department no AD seja igual a “Segurança”.
Passo a passo:
Verifique se o atributo Department foi mapeado na integração com o AD.
Vá em Policy > Policy Sets > Authorization Policy
Crie uma condição: IF AD:Department EQUALS "Segurança" THEN Apply VLAN 60 + SGT “Security”
Simples e altamente eficaz. Você está aplicando segmentação baseada em um campo organizacional real, sem depender de múltiplos grupos de AD.
2. Adicionando um Dicionário RADIUS de um Fabricante Externo no Cisco ISE
Em muitos cenários de integração — como com firewalls Palo Alto, Fortinet, F5, Aruba, etc. — é comum que esses dispositivos utilizem atributos RADIUS proprietários ou Vendor-Specific Attributes (VSAs) para enviar dados adicionais em pacotes RADIUS.
Por padrão, o Cisco ISE reconhece os atributos mais comuns do protocolo. No entanto, se você quiser consumir atributos personalizados de outro fabricante, precisará importar ou criar um dicionário RADIUS específico para esse vendor.
Exemplo de uso:
Você deseja criar uma regra no ISE baseada em um atributo específico enviado por um firewall Palo Alto, como PaloAlto-User-Group.
Passo a passo: como adicionar um dicionário RADIUS personalizado
Acesse o menu de dicionários: No ISE 3.1 ou superior, vá em: Policy > Policy Elements > Dictionaries > RADIUS > RADIUS Vendors
Clique em “Add” (Adicionar)
Preencha os campos principais:
Vendor Name: nome do fabricante (ex: PaloAlto)
Vendor ID: o ID atribuído pelo IANA (ex: 25461 para Palo Alto)
Vendor Type: selecione RADIUS
Clique em Submit
Adicione os atributos específicos do vendor: Após criar o dicionário, clique sobre ele e vá em “Attributes” > “Add”. Exemplo de atributo:
Name: PaloAlto-User-Group
Attribute ID: conforme a documentação do fabricante (ex: 1)
Data Type: String, Integer, Boolean, etc.
Length: se necessário
Direction: geralmente “Input” (se o ISE vai ler esse valor)
Clique em Submit para salvar o atributo.
Usar o novo atributo em políticas: Agora que o atributo faz parte de um dicionário válido, você pode utilizá-lo em condições dentro de Authorization Policies, exatamente como faria com um atributo RADIUS nativo.
Onde obter os detalhes dos atributos?
Consulte a documentação oficial do fabricante (Palo Alto, Fortinet, etc.) para obter:
O Vendor ID (IANA)
A lista de atributos disponíveis
Os Vendor-Specific Attribute IDs e seus tipos
Exemplo: O Vendor ID da Palo Alto Networks é 25461. Um dos atributos mais usados é o PaloAlto-User-Group, que pode ser utilizado para segmentação baseada em grupos de usuários na rede.
Benefícios dessa integração
Facilita a integração com soluções de segurança de terceiros em ambientes heterogêneos
Permite que o ISE reconheça e atue com base em atributos personalizados enviados por firewalls, proxies ou NACs externos
Expande a capacidade de decisões contextuais com dados além do AD ou RADIUS padrão
Conclusão
Os dicionários no Cisco ISE são mais do que uma lista de atributos — eles são a base para políticas inteligentes, dinâmicas e contextuais. Ao dominar seu uso, você:
Cria regras mais precisas e alinhadas ao negócio
Reduz erros ao aplicar permissões
Ganha flexibilidade para integrações com AD, firewalls, posture e profiling
Imagine que o Cisco ISE (Identity Services Engine) é como o controle de acesso de um prédio inteligente. Quando alguém tenta entrar, o sistema verifica quem é e decide aonde essa pessoa pode ir, com base em regras pré-definidas. Esse é o papel das políticas no ISE: verificar e decidir.
Neste artigo, vamos explorar:
O que são os Policy Sets no ISE
Como funciona a lógica “IF → THEN” (SE → ENTÃO)
Como o ISE aplica ações como VLAN, ACL, SGT
Exemplos práticos e dicas para aplicar no seu ambiente
1. O que são os Policy Sets no Cisco ISE?
Os Policy Sets são o ponto de entrada da lógica de decisão do ISE. Eles funcionam como grandes agrupadores de políticas que separam diferentes contextos de acesso, como:
Acesso cabeado com 802.1X
Dispositivos legados via MAB (MAC Authentication Bypass)
Visitantes usando WebAuth
Conexões VPN, SSID específicos, etc.
O ISE analisa os Policy Sets de cima para baixo, e entra no primeiro que corresponder à requisição recebida (com base em atributos como protocolo, switch, SSID, porta, etc).
IF protocolo = EAP-TLS AND NAS-Port-Type = Ethernet THEN usar o Policy Set “Acesso Corporativo”
Cada Policy Set contém:
Authentication Policy (quem está se conectando?)
Authorization Policy (o que esse usuário/dispositivo pode fazer?)
2. Como funciona a lógica IF → THEN no ISE
O motor de decisão do Cisco ISE é baseado em estruturas condicionais, muito semelhantes à lógica de programação:
IF [Condição for verdadeira] THEN [Aplique determinada ação]
Essa lógica é aplicada em três níveis principais:
a) Policy Set Selection
IF protocolo = EAP THEN usar o Policy Set "Acesso Wireless"
b) Authentication Policy
IF método = EAP-PEAP AND origem = Switch 01 THEN verificar credencial no Active Directory
c) Authorization Policy
IF grupo_AD = "TI" AND tipo_dispositivo = Laptop THEN aplicar VLAN 10 + SGT Admin + ACL liberada
Essas regras são sempre avaliadas de cima para baixo, e o ISE aplica a primeira regra que for compatível com os atributos da sessão.
3. Ações aplicadas pelo ISE (o “THEN”)
Depois que o ISE entende quem está se conectando e com quais atributos, ele aplica uma série de ações que definem o comportamento de rede para aquele dispositivo:
Tipo de ação
Exemplos
VLAN Assignment
VLAN 10 para TI, VLAN 30 para visitantes
SGT (TrustSec)
SGT Admin, HR, Printer – para microsegmentação
ACL/DACL
Downloadable ACLs com restrições de acesso
Redirecionamento
Para portal de convidados, posture, BYOD, etc.
Autorização negativa
VLAN de quarentena ou DACL “deny-all”
4. Exemplo prático de fluxo de decisão
Cenário:
Funcionário do RH acessando via 802.1X em switch
Impressora HP conectada via MAB
Visitante acessando via WebAuth
Como o ISE decide:
IF autenticação via 802.1X AND grupo AD = "RH" THEN aplicar VLAN 20 + SGT RH
IF autenticação via MAB AND perfil do endpoint = Printer THEN aplicar VLAN 40 + SGT Printer
IF autenticação via WebAuth THEN aplicar VLAN 30 + ACL restritiva
E se nada for compatível?
IF nenhuma condição for satisfeita THEN aplicar VLAN de quarentena + DACL deny-all
Diagrama simplificado da lógica
flowchart TD A[Solicitação de conexão] --> B{Policy Set Match?} B -- Sim --> C[Authentication Policy] C --> D{Autenticação válida?} D -- Sim --> E[Authorization Policy] E --> F{Grupo = TI?} --> G[Aplique VLAN 10 + SGT Admin] F --> H{Dispositivo = Impressora?} --> I[Aplique VLAN 40 + ACL] D -- Não --> Z[Aplicar VLAN de quarentena ou negar acesso]
Conclusão
O Cisco ISE não é uma “caixa preta”. Ele funciona com base em lógica condicional simples, clara e previsível. Entendendo os blocos de decisão (Policy Set, AuthZ/AuthC) e como as regras “IF → THEN” se aplicam, você consegue:
Criar políticas mais seguras e granulares
Automatizar respostas com base em contexto
Reduzir ACLs e VLANs fixas, com TrustSec (SGTs)
Melhorar a experiência do usuário com decisões inteligentes
Perguntas Frequentes sobre Políticas no Cisco ISE (FAQ)
1. O que acontece se nenhuma regra for compatível com a sessão?
O ISE aplica a última regra default (geralmente negativa), como uma VLAN de quarentena ou uma DACL com bloqueio total. Isso evita acessos não autorizados.
2. Qual a diferença entre Authentication e Authorization Policy?
Authentication verifica quem é o usuário/dispositivo e se as credenciais são válidas.
Authorization decide o que ele pode fazer na rede, como VLAN, ACL ou SGT.
3. Posso usar atributos de dispositivos (profiling) nas regras de autorização?
Sim. O ISE permite usar atributos de profiling, como tipo de sistema operacional ou fabricante, para criar regras mais granulares.
4. O ISE avalia todas as regras de Authorization ou só a primeira compatível?
O ISE avalia as regras de cima para baixo e aplica apenas a primeira que for compatível. A ordem das regras é extremamente importante.
5. É possível usar grupos do Active Directory como condição de autorização?
Sim. O ISE pode integrar-se ao AD e utilizar grupos de segurança como parte da lógica condicional (ex: grupo = “Financeiro”).
6. Posso aplicar múltiplas ações (ex: VLAN + ACL + SGT) ao mesmo tempo?
Sim. Uma única regra de autorização pode combinar várias ações de controle de acesso de forma simultânea, dependendo da infraestrutura de rede compatível.
No mundo digital de hoje, onde ameaças cibernéticas evoluem constantemente, proteger sua rede não é apenas uma opção—é uma necessidade. O Cisco Identity Services Engine (ISE) é uma ferramenta poderosa que ajuda as organizações a controlar quem e o que está acessando seus recursos de rede. Mas como o ISE consegue fazer isso de forma tão eficaz? A resposta está nas suas personas.
As personas no Cisco ISE representam diferentes papéis ou funções que os nós podem desempenhar dentro do sistema, trabalhando em conjunto para fornecer uma solução completa de segurança e gerenciamento de acesso. Vamos explorar por que elas são tão importantes.
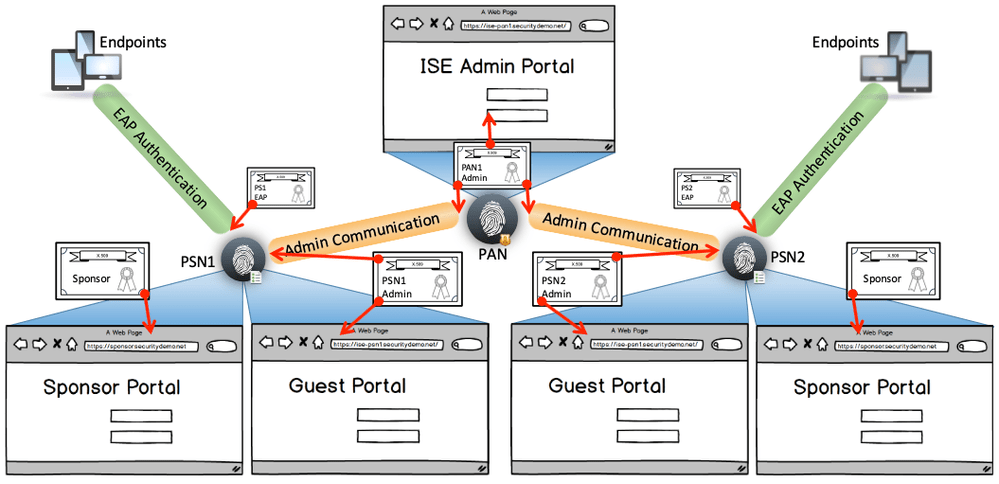
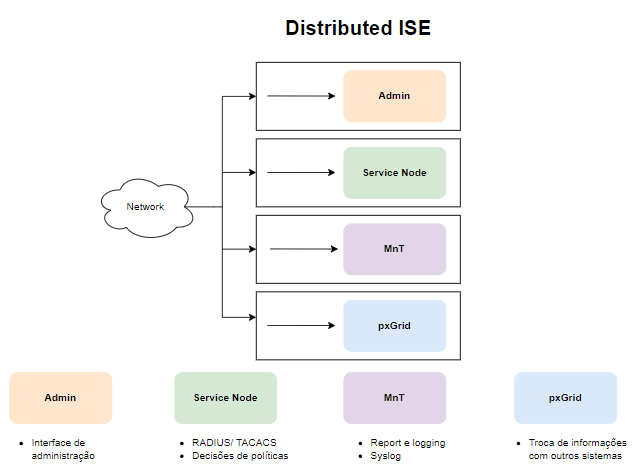
Neste artigo vamos falar sobre como é essa estrutura de Personas existente no Cisco Identity Service Engine (ISE). Existem quatro tipos principais de personas: Admin, Policy Service Node (PSN), Monitoring and Troubleshooting (MnT) e Platform Exchange Grid (pxGrid), vamos entender o papel de cada um.
Entendendo o papel de cada Persona
Administration Persona (Policy Administration Node – PAN):
A persona de Admin fornece as interfaces de gerenciamento, tanto a interface gráfica baseada na web (GUI) quanto a interface de linha de comando (CLI), para configurar e administrar todo o sistema do Cisco ISE.
Funções Principais:
Configuração do Sistema: Permite aos administradores definir configurações globais, como políticas de autenticação, autorização e perfilamento.
Gerenciamento de Políticas: Criação e gerenciamento de políticas de acesso à rede, incluindo regras de segurança e conformidade.
Administração de Certificados: Gerencia certificados digitais para comunicação segura entre nós e dispositivos.
Gerenciamento de Nós: Adiciona, remove e gerencia outros nós e personas dentro da implantação do ISE.
Em um ambiente de implementação distribuído é possível pode ter um máximo de dois nós rodando a função de Administration Persona. O Administration Persona pode ser aplicado em um servidor standalone ou em ambiente distribuído.
Persona de Serviço (Policy Service Node – PSN)
Conhecido como Nó de Serviço, o PSN é responsável por aplicar as políticas definidas e fornecer serviços de acesso à rede, como autenticação, autorização, perfilamento e avaliação de postura.
Funções Principais:
Processamento AAA: Lida com solicitações de Autenticação, Autorização e Contabilização (AAA) de dispositivos de rede.
Serviços RADIUS e TACACS+: Fornece protocolos para autenticar usuários e dispositivos que tentam acessar a rede.
Perfilamento de Dispositivos: Identifica e classifica dispositivos na rede com base em características observadas.
Avaliação de Postura: Verifica se os dispositivos estão em conformidade com as políticas de segurança antes de conceder acesso.
Persona de Monitoramento e Solução de Problemas (Monitoring and Troubleshooting – MnT)
A persona MnT coleta, armazena e analisa logs e dados operacionais do Cisco ISE, fornecendo ferramentas para monitoramento, relatórios e solução de problemas.
Funções Principais:
Coleta de Logs: Agrega logs de autenticação, autorização, contabilização e eventos do sistema de todos os nós PSN.
Relatórios e Dashboards: Oferece relatórios predefinidos e personalizados, além de painéis para visualizar o status do sistema e tendências.
Análise e Solução de Problemas: Auxilia na identificação e resolução de problemas relacionados ao acesso à rede e desempenho do sistema.
Alertas e Notificações: Configura alertas baseados em eventos ou condições específicas para proatividade na gestão da rede.
Persona Platform Exchange Grid (pxGrid)
Descrição: O pxGrid é uma plataforma que permite a integração e o compartilhamento seguro de informações contextuais entre o Cisco ISE e outras soluções de segurança de rede.
Funções Principais:
Integração de Sistemas: Conecta o ISE a produtos de segurança de terceiros, como firewalls, sistemas de prevenção de intrusões e SIEMs.
Compartilhamento de Contexto: Distribui informações sobre usuários, dispositivos, sessões e políticas para melhorar a inteligência de segurança.
Automação de Respostas: Permite que sistemas conectados tomem ações baseadas em políticas, como isolamento de dispositivos comprometidos.
Escalabilidade e Flexibilidade: Utiliza um modelo de publicação/assinatura para troca eficiente de informações em grandes ambientes.
Resumo Geral:
Admin: Centraliza a configuração e o gerenciamento da aplicação do ISE.
PSN (Service Node): Executa as políticas de segurança, processando solicitações de acesso à rede.
MnT: Fornece visibilidade e insights operacionais por meio de monitoramento e relatórios.
pxGrid: Facilita a colaboração e integração com outras soluções de segurança, ampliando a capacidade de resposta a ameaças.
Agora que entendemos como cada persona funciona, vamos entender os dois modos de implementação possíveis do ISE, Standalone e Distributed.
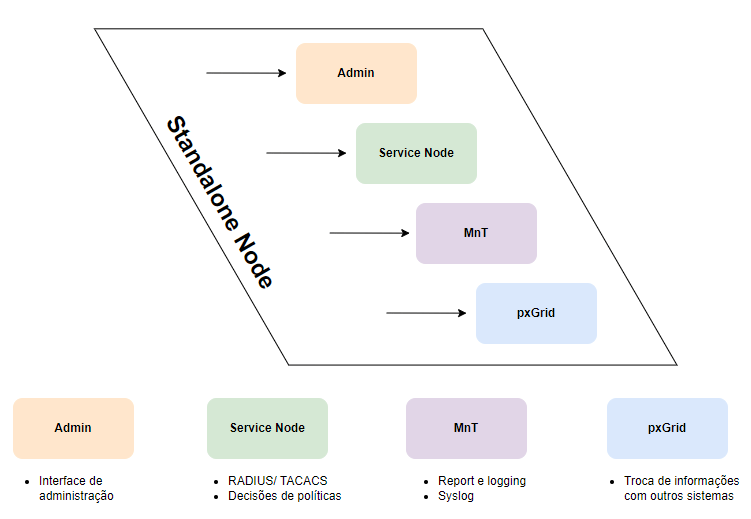
Modo Standalone
No modo Standalone, toda a funcionalidade do Cisco ISE é executada em um único nó ou servidor. Este nó único incorpora todas as personas (Admin, Policy Service Node – PSN, Monitoring and Troubleshooting – MnT e pxGrid) em uma única instalação.
Funcionamento
Implementação Simples: Ideal para ambientes menores ou de teste, onde a carga de trabalho é limitada e a alta disponibilidade não é um requisito crítico.
Todas as Personas em um Único Nó: O servidor Standalone lida com a administração, processamento de políticas, monitoramento e integração com outros sistemas, tudo a partir de um único ponto.
Facilidade de Gerenciamento: Com apenas um nó para gerenciar, a configuração e manutenção são simplificadas.
Cenários de Uso
Ambientes de Laboratório ou Teste: Onde o objetivo é avaliar ou demonstrar as capacidades do Cisco ISE.
Pequenas Empresas: Com um número limitado de usuários e dispositivos, onde a carga não excede a capacidade de um único servidor.
Implementações Temporárias: Situações onde uma solução rápida é necessária sem a complexidade de uma arquitetura distribuída.
Vantagens e Limitações
Vantagens:
Implementação e configuração rápidas.
Menor custo inicial de hardware e licenciamento.
Simplicidade na gestão diária.
Limitações:
Escalabilidade Limitada: Não adequado para grandes ambientes ou crescimento futuro.
Ausência de Redundância: Se o nó único falhar, todos os serviços do ISE ficam indisponíveis.
Desempenho: Pode sofrer com lentidão se sobrecarregado.
Modo Distribuído
No modo Distributed, o Cisco ISE é implementado em múltiplos nós, distribuindo as diferentes personas entre eles. Isso permite escalabilidade, redundância e melhor desempenho, atendendo às necessidades de redes de médio a grande porte.
Funcionamento
Segregação de Personas: As diferentes funções (Admin, PSN, MnT, pxGrid) são atribuídas a nós dedicados ou compartilhadas conforme a necessidade.
Escalabilidade Horizontal: Novos nós podem ser adicionados para suportar cargas de trabalho crescentes.
Alta Disponibilidade: Implementação de nós redundantes para evitar pontos únicos de falha.
Sincronização e Replicação: Os dados de configuração e políticas são sincronizados entre os nós Admin, enquanto os dados operacionais são agregados pelos nós MnT.
Vantagens
Escalabilidade: Capacidade de adicionar mais nós para suportar aumento de carga.
Redundância: Múltiplos nós evitam pontos únicos de falha, aumentando a resiliência.
Desempenho Otimizado: Distribuição da carga de trabalho melhora a eficiência do sistema.
Flexibilidade: Permite customizar a implantação de acordo com as necessidades específicas da rede.
Cenários de Uso
Médias e Grandes Empresas: Onde há um grande número de usuários, dispositivos e solicitações de autenticação.
Ambientes que Exigem Alta Disponibilidade: Redes críticas que não podem tolerar tempo de inatividade.
Ambientes Distribuídos Geograficamente: Onde os PSNs podem ser posicionados próximos aos usuários para reduzir a latência.
Considerações
Complexidade: Requer planejamento cuidadoso e conhecimento para implementar e gerenciar.
Custo: Investimento maior em hardware, licenças e manutenção.
Gerenciamento Centralizado: Necessidade de sincronização entre nós e monitoramento constante.
Comparação entre Standalone e Distributed
Escalabilidade:
Standalone: Limitada, adequado para pequenas cargas.
Distributed: Altamente escalável, suporta crescimento da rede.
Redundância:
Standalone: Não possui; falha do nó resulta em perda total de serviço.
Distributed: Suporta alta disponibilidade com nós redundantes.
Complexidade de Implementação:
Standalone: Simples e rápido de configurar.
Distributed: Mais complexo, requer planejamento e recursos adicionais.
Desempenho:
Standalone: Pode ser afetado sob carga pesada.
Distributed: Desempenho otimizado através da distribuição de carga.
Custo:
Standalone: Menor investimento inicial.
Distributed: Maior investimento, mas necessário para ambientes críticos.
A escolha entre os modos Standalone e Distributed do Cisco ISE depende das necessidades específicas da organização:
Modo Standalone é ideal para ambientes menores, onde simplicidade e baixo custo são prioridades, e os requisitos de desempenho e disponibilidade são modestos.
Modo Distributed é necessário em ambientes maiores ou críticos, onde a escalabilidade, redundância e desempenho são essenciais para suportar uma grande quantidade de usuários e dispositivos, além de garantir a continuidade do serviço.
Ambos os modos oferecem as funcionalidades completas do Cisco ISE, mas o modo Distributed permite uma abordagem mais robusta e flexível, alinhada com as demandas de redes corporativas modernas e complexas.
Conclusão
Em suma, o Cisco ISE, com suas personas interconectadas e modos de operação adaptáveis, oferece uma solução abrangente que capacita as organizações a alcançar excelência em segurança de rede e eficiência operacional. É uma ferramenta essencial para navegar no complexo panorama da segurança cibernética atual, garantindo que sua rede permaneça segura, eficiente e preparada para o futuro.
Links de referência
Para aprofundar ainda mais seu conhecimento no Cisco ISE, compartilho alguns links úteis:
Com a crescente dependência de redes corporativas para a realização de operações críticas, a segurança dessas redes tornou-se uma preocupação primordial. A tecnologia MacSec (Media Access Control Security) surgiu como uma solução robusta para garantir a integridade e confidencialidade dos dados transmitidos em redes Ethernet. Este artigo explora a definição de MacSec, sua evolução histórica e como sua implementação pode elevar os níveis de segurança em uma rede corporativa.
O que é MacSec?
MacSec, ou Media Access Control Security, é um padrão de segurança definido pelo IEEE 802.1AE que fornece autenticação, integridade e confidencialidade para o tráfego de dados nas camadas inferiores da rede, especificamente na camada de enlace (Layer 2). O objetivo principal do MacSec é proteger os dados enquanto eles são transmitidos entre dispositivos na rede, evitando ataques como interceptação, adulteração e repetição de pacotes.
Vantagens do MacSec
O MacSec oferece múltiplas vantagens em comparação com outras tecnologias de segurança de rede:
1. Criptografia e Integridade de Dados: MacSec criptografa cada pacote de dados na camada 2, garantindo que os dados não possam ser lidos ou alterados durante o trânsito sem detecção.
2. Proteção contra Ataques de Interceptação: Ao operar na camada de enlace, o MacSec protege contra ataques como spoofing e man-in-the-middle, que são comuns em redes menos seguras.
3. Desempenho: Diferente de soluções que operam em camadas superiores, o MacSec tem um impacto mínimo no desempenho da rede, pois utiliza hardware específico para a criptografia e descriptografia dos pacotes.
4. Flexibilidade e Escalabilidade: É possível implementar o MacSec em uma ampla gama de dispositivos de rede, de switches a roteadores, e a tecnologia é escalável de pequenas a grandes redes.
Evolução Histórica do MacSec
Início e Desenvolvimento
Desenvolvido e padronizado pelo IEEE como 802.1AE em 2006, o MacSec surgiu como uma resposta às crescentes demandas por segurança em redes locais (LANs) e metropolitanas (MANs). Originalmente concebido para proteger redes Ethernet, o MacSec foi evoluindo ao longo dos anos com adições significativas, como o suporte a redes ponto a ponto e a expansão para proteger também as redes virtuais (VLANs).
As primeiras implementações de MacSec concentravam-se principalmente em ambientes corporativos de grande escala, onde a integridade e a confidencialidade dos dados são críticas. Com o tempo, a tecnologia se adaptou para oferecer soluções também para pequenas e médias empresas, graças à redução de custos e à maior facilidade de implementação.
Adaptação e Adoção
Com a introdução do 802.1AE, os fabricantes de hardware e software começaram a integrar suporte para MacSec em seus dispositivos. A adoção do MacSec foi gradual, inicialmente limitado a ambientes de alta segurança. No entanto, à medida que as ameaças à segurança cibernética evoluíram e se tornaram mais sofisticadas, a implementação de MacSec em redes corporativas tornou-se uma prática recomendada.
Benefícios do MacSec na Segurança de Redes Corporativas
Proteção Contra Ameaças Internas e Externas
MacSec fornece uma linha de defesa crítica contra ameaças internas e externas. Ao criptografar os dados na camada de enlace, ele protege contra a interceptação de informações sensíveis por agentes maliciosos dentro da rede (ameaças internas) e ataques de interceptação de dados por invasores externos.
Autenticação e Controle de Acesso
MacSec utiliza mecanismos de autenticação robustos para garantir que apenas dispositivos autorizados possam participar da rede. Isso impede que dispositivos não autorizados acessem ou interfiram no tráfego da rede, protegendo contra ataques de dispositivos não confiáveis.
Integridade e Confidencialidade de Dados
Ao garantir a integridade e confidencialidade dos dados, MacSec assegura que as informações transmitidas não sejam alteradas ou acessadas por partes não autorizadas. Isso é particularmente importante para empresas que lidam com informações sensíveis ou regulamentadas, onde a integridade dos dados é crítica.
Simplificação da Segurança em Redes Ethernet
MacSec simplifica a implementação de segurança em redes Ethernet ao fornecer uma solução integrada para autenticação, integridade e criptografia. Isso reduz a necessidade de múltiplas soluções de segurança, facilitando a gestão e a manutenção da segurança da rede.
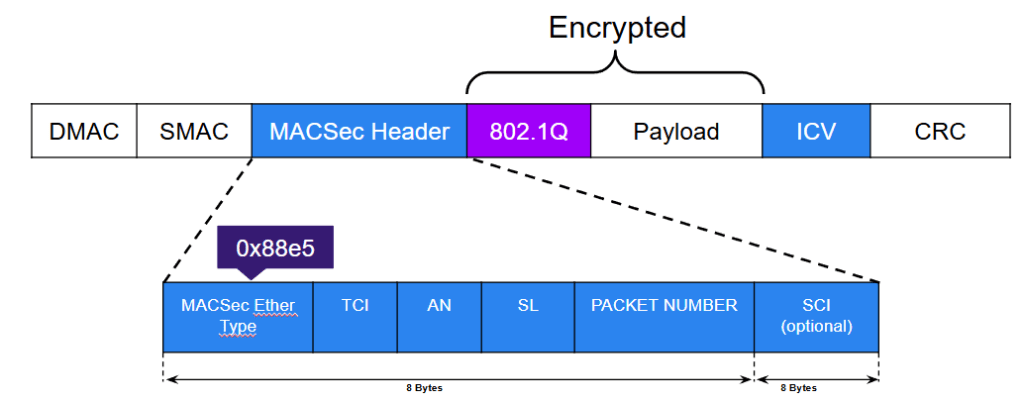
Estrutura de um frame 802.1AE
A estrutura de um frame 802.1AE, também conhecido como MacSec (Media Access Control Security), é uma extensão do frame Ethernet padrão que inclui campos adicionais para fornecer autenticação, integridade e confidencialidade dos dados transmitidos. Vamos detalhar os componentes de um frame 802.1AE e como eles se integram ao frame Ethernet.
Um frame 802.1AE é composto por várias partes principais:
Cabeçalho Ethernet (Ethernet Header)
Campo de Tipo/Comprimento (Type/Length Field)
Cabeçalho de Segurança MacSec (SecTAG – Security Tag)
Dados Encriptados (Encrypted Data)
Código de Verificação de Integridade (ICV – Integrity Check Value)
Trailer Ethernet (Ethernet Trailer)
Componentes em Detalhe
1. Cabeçalho Ethernet (Ethernet Header)
O frame 802.1AE (MacSec) é uma extensão do frame Ethernet padrão que inclui campos adicionais para autenticação, integridade e confidencialidade dos dados. Ao incorporar o SecTAG, os dados encriptados e o ICV, MacSec oferece uma camada robusta de segurança para a transmissão de dados em redes Ethernet, protegendo contra uma ampla gama de ameaças de segurança.
O cabeçalho Ethernet padrão contém os seguintes campos:
MAC deDestino (Destination MAC Address): O endereço MAC do destinatário.
MAC de Origem (Source MAC Address): O endereço MAC do remetente.
Campo de Tipo/Comprimento (Type/Length Field): Indica o protocolo de camada superior ou o comprimento do frame.
Estrutura de frame 802.1AE
2. Campo de Tipo/Comprimento (Type/Length Field)
Neste contexto, o campo de Tipo/Comprimento é configurado para indicar que o frame contém um cabeçalho de segurança MacSec. O valor específico utilizado é 0x88E5, que identifica um frame MacSec.
3. Cabeçalho de Segurança MacSec (SecTAG)
O SecTAG é um campo adicionado pelos mecanismos de segurança MacSec. Ele contém várias sub-campos que ajudam na autenticação e integridade dos dados:
Tag Control Information (TCI): Indica o uso de proteção criptográfica e o tipo de frame (unicast, multicast).
Packet Number (PN): Um contador que garante a unicidade de cada frame, ajudando a prevenir ataques de repetição.
Association Number (AN): Identifica a chave de associação usada para proteger o frame.
4. Dados Encriptados (Encrypted Data)
Os dados reais da camada superior (payload) são encriptados para garantir a confidencialidade. Apenas dispositivos autorizados e que possuem a chave de decriptação correta podem acessar o conteúdo original.
5. Código de Verificação de Integridade (ICV)
O ICV é um valor calculado a partir do conteúdo do frame e é usado para verificar a integridade dos dados. Se o ICV calculado no receptor não corresponder ao ICV enviado, o frame é considerado adulterado e descartado.
6. Trailer Ethernet (Ethernet Trailer)
O trailer Ethernet geralmente contém o valor do FCS (Frame Check Sequence), que é usado para detectar erros no frame transmitido.
Configuração com IBNS1 e IBNS2
Antes de vermos na prática como o MacSec é configurado, vamos entender os conceitos sobre IBNS (Identity-Based Networking Services) nas versões 1 e 2. Para os exemplos de configuração será utilizado o padrão mais recente IBNS2.
IBNS (Identity-Based Networking Services) é um conjunto de soluções desenvolvidas pela Cisco para fornecer controle de acesso e políticas de segurança baseadas na identidade dos usuários e dispositivos. Existem duas versões principais de IBNS: IBNS1 e IBNS2. Abaixo, vamos detalhar as diferenças entre esses dois padrões.
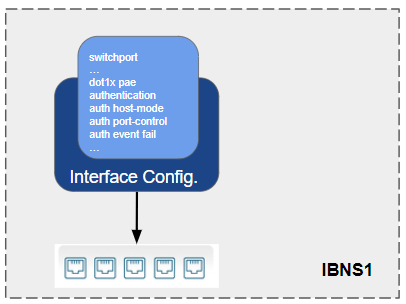
IBNS1
Arquitetura e Funcionamento:
Baseado em Portas: IBNS1 utiliza autenticação 802.1X em portas individuais. Cada porta pode ser configurada para autenticar os dispositivos conectados a ela.
Configuração Estática: As políticas de segurança e acesso são configuradas estaticamente nas portas dos switches e roteadores.
Controle de Acesso: Utiliza ACLs (Access Control Lists) e VLANs (Virtual Local Area Networks) para controlar o acesso dos dispositivos autenticados.
Flexibilidade Limitada: A configuração e a gestão das políticas são menos flexíveis, uma vez que dependem de configurações estáticas.
Características Principais:
Autenticação 802.1X: Suporta autenticação de dispositivos via 802.1X.
ACLs e VLANs: Utiliza ACLs e VLANs para aplicar políticas de segurança e segmentação.
Gerenciamento de Políticas: As políticas são aplicadas diretamente nas portas dos dispositivos de rede.
Cisco IBNS1
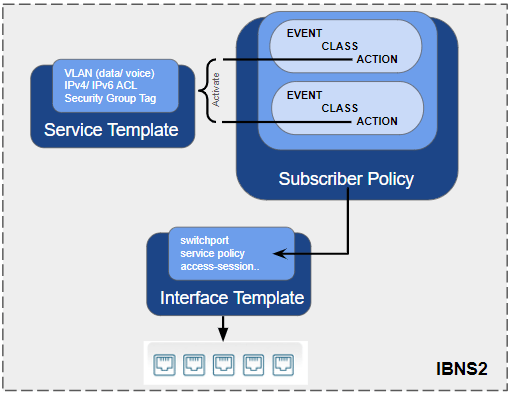
IBNS2
Arquitetura e Funcionamento:
Baseado em Sessões: IBNS2 evoluiu para uma abordagem baseada em sessões, permitindo maior flexibilidade e dinamismo na aplicação de políticas.
Configuração Dinâmica: As políticas são configuradas dinamicamente e aplicadas com base na identidade do usuário ou dispositivo, permitindo uma melhor adaptação às mudanças no ambiente de rede.
Segmentação e Automação: Utiliza técnicas avançadas de segmentação e automação para aplicar políticas de segurança de maneira mais eficiente e adaptável.
Cisco TrustSec: Integra-se com a tecnologia Cisco TrustSec para fornecer segmentação baseada em identidade e políticas de segurança dinâmicas.
Características Principais:
Segmentação Baseada em Identidade: Permite segmentar a rede com base na identidade do usuário ou dispositivo.
Políticas Dinâmicas: As políticas de segurança são aplicadas dinamicamente, adaptando-se às necessidades e ao contexto de cada sessão.
Automação: Suporte para automação de políticas e respostas a eventos de segurança.
Suporte para SD-Access: Integrado com a solução Cisco SD-Access, permitindo uma abordagem de rede definida por software para segurança e segmentação.
Cisco IBNS2
Comparação Resumida
Característica
IBNS1
IBNS2
Abordagem
Baseado em portas
Baseado em sessões
Configuração
Estática
Dinâmica
Controle de Acesso
ACLs e VLANs
Segmentação baseada em identidade
Flexibilidade
Limitada
Alta
Automação
Baixa
Alta
Integração com TrustSec
Não
Sim
Suporte para SD-Access
Não
Sim
Tabela com as diferenças entre IBNS1 e IBNS2
A principal diferença entre IBNS1 e IBNS2 está na abordagem de implementação e flexibilidade. Enquanto IBNS1 utiliza uma configuração mais estática e baseada em portas, IBNS2 oferece uma solução dinâmica e baseada em sessões, permitindo uma maior flexibilidade, automação e segurança adaptativa. A escolha entre os dois depende das necessidades específicas da rede e dos requisitos de segurança da organização.
Fundamentos de AAA (Authentication, Authorization, Accounting)
Autenticação, Autorização e Auditoria
AAA, que significa Authentication, Authorization, and Accounting (Autenticação, Autorização e Auditoria), é um framework crucial em redes e segurança da informação para gerenciar quem pode acessar os recursos, o que eles podem fazer e como registrar suas atividades. Vamos explorar as diferenças e funções de cada um dos três componentes de AAA.
Authentication (Autenticação)
Definição: Autenticação é o processo de verificar a identidade de um usuário, dispositivo ou sistema que deseja acessar um recurso.
Função:
Verificação de Identidade: A autenticação confirma que o usuário ou dispositivo é realmente quem diz ser. Isso é feito através de credenciais, como senhas, certificados digitais, tokens ou biometria.
Métodos Comuns: Incluem senhas, cartões inteligentes, autenticação de dois fatores (2FA) e certificados digitais.
Exemplo: Quando você faz login em uma rede com um nome de usuário e senha, o sistema verifica se essas credenciais correspondem a um usuário autorizado.
Authorization (Autorização)
Definição: Autorização é o processo de conceder ou negar permissões aos usuários ou dispositivos autenticados para acessar recursos específicos.
Função:
Controle de Acesso: Após a autenticação, a autorização determina quais recursos e serviços o usuário ou dispositivo pode acessar e que operações pode realizar.
Políticas de Acesso: Baseia-se em políticas que definem os direitos de acesso, como permissões de leitura, escrita ou execução em um sistema de arquivos ou acesso a determinadas áreas de uma rede.
Exemplo: Um usuário autenticado pode ser autorizado a acessar arquivos específicos em um servidor, mas não a modificar configurações do sistema.
Accounting (Auditoria)
Definição: Auditoria é o processo de registrar e monitorar as atividades dos usuários e dispositivos na rede.
Função:
Registro de Atividades: Registra quem fez o quê, quando e onde. Isso inclui logins, acessos a recursos, modificações feitas e duração das sessões.
Monitoramento e Relatórios: Fornece dados para análise de segurança, conformidade e faturamento. Ajuda a identificar comportamentos anômalos e pode ser usado para investigações de segurança.
Exemplo: Um sistema de contabilidade registra que um usuário acessou um servidor específico, baixou um arquivo e saiu da sessão às 10:30 AM.
Comparação Resumida
Componente
Função Principal
Exemplos de Uso
Authentication
Verificar a identidade do usuário ou dispositivo
Login com nome de usuário e senha
Authorization
Controlar o acesso aos recursos
Permissão para acessar arquivos
Accounting
Registrar e monitorar atividades
Logs de acesso e uso de recursos
Comparação entre AAA
Como Funcionam Juntos
Em uma implementação de AAA típica, esses componentes funcionam em conjunto para fornecer um controle de acesso robusto e seguro:
Autenticação: O usuário fornece suas credenciais. O sistema verifica se são válidas.
Autorização: Uma vez autenticado, o sistema verifica as permissões do usuário e concede acesso aos recursos autorizados.
Auditoria: Todas as atividades do usuário são registradas para fins de monitoramento e auditoria.
A combinação de Autenticação, Autorização e Auditoria forma um framework integral para gerenciar a segurança e o controle de acesso em redes e sistemas de informação. Cada componente desempenha um papel crucial: a autenticação assegura que apenas usuários legítimos possam acessar a rede, a autorização define o que esses usuários podem fazer, e a auditoria monitora e registra suas atividades para garantir conformidade e segurança contínuas.
Métodos de autenticação
A autenticação de rede é um componente crucial para garantir que apenas usuários e dispositivos autorizados possam acessar recursos de rede. Existem vários métodos de autenticação utilizados para este fim, cada um com suas próprias características e casos de uso específicos. Vamos explorar as diferenças entre IEEE 802.1X, MAC Authentication Bypass (MAB), Web Authentication e EasyConnect.
IEEE 802.1X
Definição: IEEE 802.1X é um padrão para controle de acesso à rede baseado em portas que fornece autenticação para dispositivos que desejam se conectar a uma LAN ou WLAN.
Características:
Autenticação Forte: Utiliza protocolos de autenticação como EAP (Extensible Authentication Protocol) para verificar a identidade dos dispositivos.
Suporte para Vários Métodos de EAP: Pode usar EAP-TLS, EAP-PEAP, EAP-TTLS, entre outros, dependendo dos requisitos de segurança.
Autenticação Mútua: Permite a autenticação tanto do cliente quanto do servidor, aumentando a segurança.
Integração com RADIUS: Normalmente, é integrado com servidores RADIUS para gestão centralizada de autenticação.
Aplicação: Comumente usado em redes corporativas e de campus para garantir que apenas dispositivos autorizados possam se conectar.
MAC Authentication Bypass (MAB)
Definição: MAB é um método de autenticação que utiliza o endereço MAC de um dispositivo como credencial para permitir o acesso à rede.
Características:
Simplicidade: Fácil de implementar, pois não requer configurações adicionais nos dispositivos cliente.
Autenticação de Dispositivos Legados: Útil para dispositivos que não suportam 802.1X, como impressoras e telefones IP.
Menor Segurança: Menos seguro, pois os endereços MAC podem ser facilmente falsificados (spoofing).
Integração com RADIUS: Pode ser integrado com servidores RADIUS para validação de endereços MAC contra uma base de dados centralizada.
Aplicação: Usado como uma medida de autenticação de fallback para dispositivos que não suportam 802.1X.
Web Authentication (WebAuth)
Definição: Web Authentication (WebAuth) é um método de autenticação onde os usuários são redirecionados para uma página web para fornecer credenciais antes de obter acesso à rede.
Características:
Portal Captive: Utiliza um portal captive onde os usuários inserem nome de usuário e senha.
Fácil de Usar: Fácil para os usuários finais, pois a autenticação é feita via navegador web.
Flexibilidade: Pode ser configurado para redirecionar para páginas de login personalizadas.
Menor Segurança Comparada ao 802.1X: Não fornece autenticação mútua e depende da segurança do navegador.
Aplicação: Comumente usado em redes Wi-Fi públicas e ambientes de convidados, onde é necessário fornecer acesso temporário à rede.
EasyConnect
Definição: EasyConnect é uma solução de autenticação que permite a integração de dispositivos na rede com uma experiência de autenticação simplificada, geralmente combinando métodos de autenticação como 802.1X e MAB.
Características:
Experiência de Usuário Simplificada: Visa simplificar a autenticação para os usuários finais, muitas vezes automatizando a seleção do método de autenticação apropriado.
Combinação de Métodos de Autenticação: Pode utilizar 802.1X para dispositivos que o suportam e MAB para aqueles que não o fazem, garantindo cobertura abrangente.
Automação e Gerenciamento: Pode incluir funcionalidades de automação para simplificar a configuração e gestão da autenticação de rede.
Flexibilidade: Adequado para ambientes mistos onde diferentes dispositivos e requisitos de autenticação coexistem.
Aplicação: Ideal para grandes redes corporativas onde a simplificação da experiência do usuário e a gestão centralizada de autenticação são críticas.
Comparação Resumida
Método
Características Principais
Casos de Uso Comuns
IEEE 802.1X
Autenticação forte via EAP, suporte para autenticação mútua, integração com RADIUS
Redes corporativas e de campus
MAC Authentication Bypass (MAB)
Utiliza endereço MAC como credencial, simples de implementar, menos seguro
Dispositivos legados, fallback para 802.1X
Web Authentication (WebAuth)
Autenticação via portal web, fácil para usuários, flexível, menor segurança comparada ao 802.1X
Redes Wi-Fi públicas, ambientes de convidados
EasyConnect
Combina métodos de autenticação, experiência simplificada, automação e gerenciamento centralizado
Grandes redes corporativas
Cada método de autenticação possui suas próprias vantagens e desvantagens, e a escolha do método adequado depende das necessidades específicas da rede e dos dispositivos conectados. IEEE 802.1X oferece a autenticação mais robusta, enquanto MAB e WebAuth são opções viáveis para dispositivos legados e ambientes onde a simplicidade e a flexibilidade são essenciais. EasyConnect proporciona uma abordagem híbrida, combinando múltiplos métodos para proporcionar uma experiência de autenticação simplificada e abrangente.
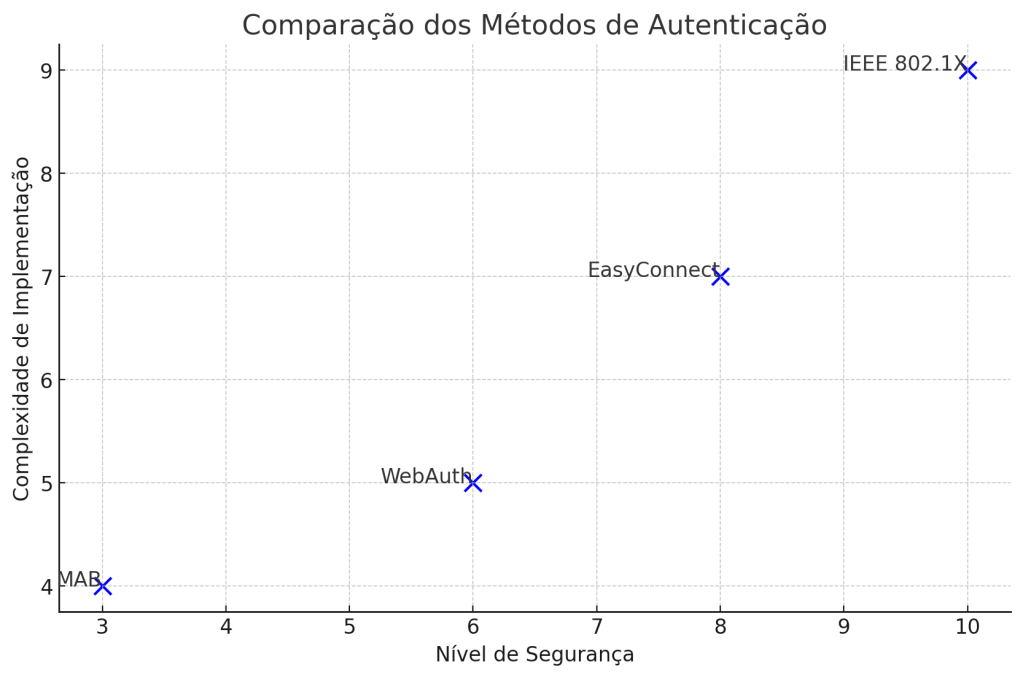
O gráfico abaixo apresenta de forma visual uma comparação entre a complexidade de implementação x o nível de segurança que cada método apresenta.
Nível de complexidade de implementação x nível de segurança
Conclusão
Nessa primeira parte do artigo focamos em apresentar os conceitos básicos sobre MacSec e métodos de autenticação. Na parte 2 vamos entender na prática como tudo isso funciona, com exemplos de configuração em um switch e com o Cisco ISE.
Qualidade de Serviço (QoS), refere-se a um conjunto de técnicas e políticas utilizadas para gerenciar o tráfego em uma rede de dados de forma a garantir um desempenho satisfatório para os diferentes tipos de aplicações e serviços.
A importância do QoS é evidente em ambientes onde vários tipos de tráfego compartilham a mesma infraestrutura de rede, como em redes corporativas, provedores de serviços de Internet (ISPs) e ambientes de nuvem. Sem um mecanismo de QoS adequado, os dados podem ser tratados de forma igual, o que pode levar a problemas de desempenho e latência para serviços que exigem uma entrega rápida e consistente.
“A função principal do QoS em uma rede de campus é gerenciar a perda de pacotes.
Alguns dos principais conceitos do QoS são:
Classificação de Tráfego:
A primeira etapa é classificar o tráfego em diferentes categorias com base em critérios como tipo de aplicação, protocolo, portas, endereços IP, etc. Por exemplo, o tráfego de voz sobre IP (VoIP) pode ser classificado de forma diferente do tráfego de navegação web.
Marcação de Pacotes:
Após a classificação, os pacotes são marcados com informações que indicam sua prioridade. Isso é feito através de campos nos cabeçalhos dos pacotes, como o campo DiffServ em pacotes IP.
Políticas de Filtragem e Marcação:
As políticas de QoS definem como os roteadores e switches devem tratar os pacotes marcados. Isso pode incluir a definição de prioridades, largura de banda mínima garantida, limites de taxa máxima, entre outros.
Gerenciamento de Largura de Banda:
O QoS permite a alocação de largura de banda com base nas necessidades das aplicações. Por exemplo, aplicações críticas como VoIP podem receber uma alocação de largura de banda prioritária para garantir uma comunicação sem interrupções.
Buffering e Escalonamento de Pacotes:
Os dispositivos de rede podem usar técnicas como filas de prioridade e escalonamento de pacotes para dar tratamento diferenciado aos pacotes de acordo com suas marcações de QoS.
Monitoramento e Medição:
É importante monitorar o desempenho da rede para garantir que as políticas de QoS estejam sendo efetivamente aplicadas e que os níveis de serviço estejam sendo atendidos.
Resiliência e Redundância:
Em ambientes críticos, podem ser implementadas estratégias de redundância para garantir a continuidade do serviço mesmo em caso de falhas na rede.
Priorização de Aplicações:
As aplicações são priorizadas com base em sua importância para o negócio. Por exemplo, tráfego de VoIP pode ter prioridade sobre tráfego de download de arquivos não essenciais.
Controle de Congestionamento:
O QoS pode ser usado para controlar a forma como a rede responde a situações de congestionamento, evitando perdas de pacotes críticos.
Oversubscription em rede de dados
Oversubscription em uma rede de dados é uma prática comum na engenharia de redes e data centers onde a largura de banda disponível para um determinado segmento da rede é maior do que a capacidade de saída agregada dessa rede. Em outras palavras, oversubscription ocorre quando a demanda potencial de largura de banda dos dispositivos conectados excede a capacidade total de transmissão da rede.
Exemplo de oversubscription em um rede de dados
Como Funciona o Oversubscription
Imagine um cenário simples: em um switch de rede, vários dispositivos estão conectados a ele. Cada dispositivo pode ter uma conexão de 1 Gbps ao switch, mas o link do switch para o roteador central pode ser de apenas 10 Gbps. Se 20 dispositivos estiverem conectados a esse switch, a demanda potencial total seria de 20 Gbps, mas o link de saída suporta apenas 10 Gbps. Assim, a razão de oversubscription seria 2:1 (20 Gbps de demanda potencial para 10 Gbps de capacidade).
Por Que Oversubscription é Utilizado
1. Custo-Efetividade: Prover a capacidade total para cada dispositivo é frequentemente caro e desnecessário, pois os dispositivos nem sempre utilizam a capacidade total simultaneamente.
2. Planejamento de Capacidade: As redes são planejadas com base no comportamento típico dos usuários e aplicativos, onde a demanda máxima simultânea raramente ocorre.
3. Eficiência de Recursos: Oversubscription permite um uso mais eficiente dos recursos de rede, já que a capacidade ociosa é minimizada.
Implicações e Desafios
1. Desempenho: Durante picos de utilização, a oversubscription pode causar congestionamento e degradação de desempenho, já que a capacidade disponível pode não ser suficiente para atender a todos os dispositivos simultaneamente.
2. Qualidade de Serviço (QoS): Para mitigar os impactos negativos, técnicas de QoS são implementadas para priorizar tráfego crítico e garantir que serviços importantes mantenham desempenho aceitável.
3. Monitoramento e Ajustes: É essencial monitorar a utilização da rede e ajustar a oversubscription conforme necessário para balancear custo e desempenho.
Determinando a relevância do Negócio
O primeiro passo antes de aplicarmos políticas de QoS inicia-se identificando os objetivos do negócio, como por exemplo:
Garantir a qualidade das ligações (VoIP);
Garantir uma alta qualidade de experiência para aplicações que utilizam vídeo;
Melhorar a produtividade minimizando os tempos de respostas da rede;
Gerenciar as aplicações do negócio;
Identificar e NÃO priorizar aplicações que não fazem parte do negócio da empresa;
Para atingir todos esses pontos, podemos classificar as aplicações em basicamente três tipos sendo elas:
Relevante: RFC 4594
Estas aplicações atendem diretamente aos negócios da empresa;
As aplicações devem ser classificadas, marcadas e tratadas de acordo com os padrões de melhores práticas recomendadas.
Default: RFC 2474
Estas aplicações devem ou não atender aos negócios da empresa (ex: HTTP/ HTTPS/ SSL)
Aplicações deste tipo devem ser tratadas com a classe default de encaminhamento.
Irrelevante: RFC 3662
Estas aplicações não suportam aos objetivos da empresa.
Essas aplicações devem ser tratadas com a classe de menor importância.
PHB, DSCP e CoS
PHB (Per-Hop Behavior):
O PHB define o comportamento que um roteador deve aplicar a um pacote com base na marcação DSCP. Em outras palavras, é a forma como um roteador trata um pacote com um determinado valor DSCP. Existem quatro classes de PHBs definidas na RFC 4594:
Expedited Forwarding (EF): É usado para tráfego de alta prioridade, geralmente associado a aplicações sensíveis à latência, como VoIP.
Assured Forwarding (AF): Oferece uma garantia de encaminhamento com algumas opções de queda. É dividido em quatro subgrupos (AF1, AF2, AF3, AF4) com diferentes níveis de prioridade.
Best Effort (BE): É o comportamento padrão para tráfego que não possui marcação DSCP específica. Recebe tratamento padrão, sem garantias de prioridade.
Class Selector (CS): Inclui as classes CS1, CS2, CS3, CS4, CS5 e CS6. Cada uma delas é uma categoria geral que pode ser usada para definir classes de serviço específicas.
DSCP (Differentiated Services Code Point):
O DSCP (Differentiated Services Code Point) e o CoS (Class of Service) são dois mecanismos distintos, mas relacionados, usados para implementar a Qualidade de Serviço (QoS) em redes de dados. Ambos são métodos para classificar e priorizar o tráfego em uma rede, mas são utilizados em diferentes camadas e tecnologias.
DSCP (Differentiated Services Code Point):
Camada de Operação: O DSCP opera na camada 3 do modelo OSI (Camada de Rede). É uma marcação no cabeçalho IP dos pacotes, onde são especificados os níveis de serviço que o pacote deve receber.
Campo de Marcação: O DSCP é um campo de 6 bits no cabeçalho IP, localizado na parte de ToS (Type of Service) ou DS (Differentiated Services).
Valores DSCP: Existem 64 valores DSCP possíveis, variando de 0 a 63. Esses valores são agrupados em diferentes classes, que indicam diferentes níveis de prioridade para o tráfego.
Tratamento de Pacotes: Roteadores e switches podem usar a marcação DSCP para tomar decisões sobre o tratamento e a priorização dos pacotes.
CoS (Class of Service):
Camada de Operação: O CoS opera na camada 2 do modelo OSI (Camada de Enlace). Ele é mais frequentemente associado ao protocolo IEEE 802.1Q, que é usado para marcação de tráfego em redes Ethernet.
Campo de Marcação: O CoS é um campo de 3 bits dentro do cabeçalho Ethernet, conhecido como campo “Priority Code Point” (PCP).
Valores CoS: Existem 8 valores CoS possíveis, variando de 0 a 7. Assim como o DSCP, esses valores indicam diferentes níveis de prioridade para o tráfego.
Tratamento de Pacotes: Dispositivos como switches Ethernet utilizam o CoS para decidir como tratar os pacotes em uma rede local.
Relação entre PHB, DSCP e CoS: A relação entre PHB, DSCP e CoS é estabelecida através de um mapeamento. Em muitos cenários, quando o tráfego passa de uma rede IP para uma rede Ethernet, o DSCP é mapeado no CoS. Isso é importante para garantir que as políticas de QoS sejam mantidas em toda a rede.
Tabela de Mapeamento – Exemplo:
PHB
DSCP Range
CoS Value
Expedited Forwarding
46
5
Assured Forwarding
10-13
2
Best Effort
0
0
Class Selector (CS1)
8
1
Class Selector (CS2)
16
2
Class Selector (CS3)
24
3
Class Selector (CS4)
32
4
Class Selector (CS5)
40
5
Class Selector (CS6)
48
6
Parâmetros Bandwidth e Priority
Dentro de uma política de QoS podemos trabalhar com dois parâmetros, bandwidth e priority. Eles são usados para controlar o tráfego em uma rede e garantir a entrega de serviços com diferentes requisitos de performance. No entanto, eles têm propósitos e comportamentos distintos:
Bandwidth (Largura de Banda):
Definição:
O parâmetro de largura de banda em uma política de QoS especifica a quantidade mínima de largura de banda que uma classe de tráfego deve receber. Ou seja, ele reserva uma parte da largura de banda total disponível para garantir que certos tipos de tráfego tenham uma alocação mínima.
Comportamento:
Se a largura de banda disponível não estiver sendo totalmente utilizada, a classe com a configuração de largura de banda garantida poderá usar o excesso de largura de banda. No entanto, se a largura de banda estiver congestionada, a classe garantida terá a sua alocação protegida, e outras classes podem sofrer redução de largura de banda.
Exemplo de Uso:
Alocar uma largura de banda mínima para tráfego de Voz sobre IP (VoIP) para garantir que as chamadas de voz tenham uma qualidade aceitável, mesmo em momentos de congestionamento de rede.
Priority (Prioridade):
Definição:
A configuração de prioridade em uma política de QoS indica que uma determinada classe de tráfego tem prioridade sobre todas as outras classes. Pacotes nesta classe serão processados antes de qualquer outra, independentemente da situação de congestionamento.
Comportamento:
Quando a configuração de prioridade está em vigor, os pacotes da classe priorizada serão enviados imediatamente, sem serem adiados por outros pacotes. Isso significa que, em momentos de congestionamento, a classe priorizada pode consumir toda a largura de banda disponível.
Importante Considerar:
Ao configurar prioridade, é crucial ter em mente que, se uma classe de tráfego com prioridade estiver usando toda a largura de banda disponível, outras classes podem experimentar atrasos significativos ou até mesmo perda de pacotes.
Diferença Chave:
Bandwidth: Garante uma alocação mínima de largura de banda para uma classe de tráfego, mas permite que a largura de banda não utilizada seja usada por outras classes.
Priority: Dá prioridade absoluta a uma classe de tráfego sobre todas as outras, o que significa que ela sempre será tratada primeiro, independentemente da situação de congestionamento. Isso pode potencialmente afetar outras classes de tráfego.
Classificação e Marcação do Tráfego
A partir das definições do modelo de negócio, temos a identificação dos seguintes tipos de tráfego a serem classificados e marcados.
Campus Qos Design Melhores Práticas
Sempre execute QoS em hardware em vez de software quando houver escolha;
Classifique e marque aplicações tão próximos de suas fontes quanto tecnicamente e administrativamente possível;
Aplique políticas para o tráfego indesejado o mais próximo possível de suas fontes;
Habilite políticas de enfileiramento em todos os nós onde existe potencial de congestionamento.
Breve exemplo de Plano de QoS para ambientes com utilização de VoIP
Em ambientes que utilizam VoIP é importante que a classificação e marcação dos pacotes seja realizada nos equipamentos de camada 2 e 3. Nos equipamentos de camada 2, o telefone IP marca o CoS para Voz e Sinalização, já o switch de rede fica responsável por fazer o mapeamento de CoS para DSCP.
Marcação de CoS (Layer 2):
O CoS é marcado no nível Layer 2 usando o campo PCP (Priority Code Point) no cabeçalho Ethernet. Para configurar isso, você pode utilizar o comando mls qos
Agora, vamos configurar a marcação de DSCP. O DSCP é aplicado no cabeçalho IP dos pacotes. Para marcar os pacotes VoIP com DSCP EF (Expedited Forwarding), por exemplo:
configure terminal class-map match-any VOIP match access-group name VOIP_ACL ! policy-map MARK_DSCP class VOIP set dscp ef
Crie uma Access Control List (ACL) para identificar o tráfego VoIP:
ip access-list extended VOIP_ACL permit udp any any range 16384 32767
Em seguida, aplique o policy-map nas interfaces relevantes (onde o tráfego VoIP ingressa na rede):
QoS é uma ferramenta essencial no design de redes de dados modernas, permitindo que os administradores de rede priorizem tráfego, garantam desempenho e otimizem a utilização de recursos para suportar uma variedade de aplicações e serviços críticos.
Uma série em que abordaremos os conceitos para elaborar um design eficiente e confiável para redes LAN.
Nessa série de artigos divididos em três partes, falaremos sobre design de uma rede Enterprise Campus LAN, a importância de criar um design eficiente e confiável para operação da rede local. Abordaremos os conceitos de uma rede tradicional em layer 2 e a diferença para o design routed access puramente em layer 3.
Introdução
Switches de camada 2 (ou switches L2) são frequentemente utilizados como meio de prover conectividade entre os clientes e a rede local. Toda segmentação do ambiente a nível de camada 2 (local area networks ou simplesmente LAN) são efetuadas nestes equipamentos.
Switches de camada 3 (switches L3) são basicamente roteadores com o “fast forwarding” feito via hardware. O encaminhamento de pacotes envolve a pesquisa de melhor rota, o decremento da contagem do TTL (time to live), o recalculo do checksum e o encaminhamento do quadro com o apropriado cabeçalho MAC para a correta porta de saída.
De forma implícita, acabamos assumindo que switches layer 3 também operam como switches Layer 2, mas isso nem sempre é verdade.
Vamos entender como combinar os switches Layer 2 e Layer 3 em um modelo de Enterprise Campus LAN.
Campus LAN – Endo-to-end VLANs ou Local VLANs
Dois dos principais modelos de design em Campus LAN são end-to-end VLANs e Local VLANs. Vamos entender como cada um desses dois modelos funcionam.
End-to-End VLANs: Modelo em que todas as VLANs são distribuídas e disponíveis em todos os switches do Campus. Neste modelo, faz-se necessário o uso de ferramentas como o STP (spanning-tree) para prevenção de loops. Nesse modelo, os usuários tem acesso a suas respectivas VLANs independentemente de sua localização física no Campus. O termo end-to-end VLANs faz referência ao fato de uma única VLAN estar presente em múltiplos switches através da rede do Campus.
Local VLANs: Neste modelo, os usuários são agrupados em VLANs dependendo de sua localização física, se um usuário move de um local para outro no campus, a VLAN que o mesmo irá utilizar será diferente. Neste caso, switches Layer 2 são utilizados para prover acesso ao usuário, já na camada de distribuição, o roteamento entre VLANs é efetuado para que o usuário consiga acessar os recursos necessários na rede.
End-to-end VLANs e Local VLANs são dois tipos de design, durante a fase de planejamento você pode optar por utilizar um mix de ambos.
End-to-End VLANs
Local VLANs
Pros: – Todas as VLANs estão disponíveis em todos os switches do Campus; – Mesmas políticas (QoS, segurança) são aplicadas aos usuários, independente de sua localização geográfica dentro do Campus.
Pros: – Modelo de design mais escalável; – Troubleshooting pode ser simplificado; – Caminhos redundantes podem ser facilmente criados.
Contras: – Todos os switches precisam estar configurados com todas as VLANs; – Mensagens de broadcast trafegam por todos os switches; – Troubleshoot pode ser um desafio neste ambiente.
Contras: – São necessários mais equipamentos com características de roteamento (switches L3).
No modelo de end-to-end VLANs, você deve levar em consideração que todos os switches trafegam dados de todas as VLANs, mesmo que não haja um usuário conectado a uma determinada VLAN em algum switch do Campus. Por este motivo, efetuar troubleshooting neste tipo de ambiente pode ser um problema, pois, o tráfego de uma simples VLAN atravessa múltiplos switches no Campus.
Já no modelo de design de Local VLANs, as VLANs que são utilizadas para a camada de acesso não devem ser estendidas além do switch de distribuição. Este modelo de design pode mitigar muitos problemas, além de prover vários benefícios como:
Determinar o caminho do tráfego: Este modelo provê de forma mais previsível o tráfego entre o switch L2 e o switch L3. Em uma eventual falha, a simplicidade do modelo permite facilita com que o problema seja isolado e rapidamente identificado.
Caminhos redundantes: Com a implementação do STP (aqui considere as diferentes versões do STP como, RSTP, PVST, MST) é possível utilizar todos os links de interconexão entre o switch L2 e o switch L3 e utilizar caminhos redundantes.
Menor ponto de falhas: Se a VLAN é local a um determinado bloco da rede e o número de usuários atrelados a essa VLAN é pequeno, uma eventual falha no layer 2 dessa VLAN acabará por impactar um número baixo de usuários.
Design Escalável: Permite um design muito mais escalável, a incorporação de novos switches ou adição de novas VLANs no ambiente de forma muito mais simples.
O modelo tradicional de Layer 2
Em um design hierárquico tradicional, o bloco de distribuição usa uma combinação protocolos e serviços de camadas 2, 3 e 4 para prover convergência, escalabilidade, segurança e gerenciamento. Neste modelo, os switches de acesso são configurados como switches L2 e encaminham o tráfego através de uplinks com os switches de distribuição através de portas configuradas como trunks. Já os switches de distribuição são configurados para suportar o encaminhamento em L2 para os switches de acesso e também encaminhamentos em L3 para a camada superior, que é o core da rede.
Neste modelo tradicional de Layer 2, a demarcação entre as camadas de L2/L3 fica a cargo dos switches de distribuição. Eles atuam o default gateways para as redes (VLANs) que são criadas no ambiente e com o encaminhamento em L3 para a camada superior. Duas características deste modelo de design:
1º: É que não é possível alcançar de forma verdadeira o balanceamento de carga entre os links, já que o STP irá bloquear caminhos redundantes. Balanceamento de carga é efetuado através de manipulação do STP e FHRP (First Hop Redundancy Protocol), enviando o tráfego de diferentes VLANs em diferentes links, porém, manipulação manual do STP e FHRP não é uma forma verdadeira de efetuar balanceamento de carga.
2º: O tempo de convergência da rede pode ser alto. Implementações do STP como RSTP tornam o tempo de convergência da rede mais rápido, mas isso só é possível alcançar com um bom nível de design de roteamento hierárquico e ajustando-se os tempos de convergência do FHRP.
Modelo de layer L2 atualizado
Neste modelo, as VLANs ainda são terminadas nos switches de distribuição (os switches continuam atuando como default gateways). A diferença é que não há mais links bloqueados através do STP. O uso de features como StackWise virtual, presente em switches da séries Catalyst 9500 por exemplo, permite que que dois switches operem logicamente como um único equipamento.
Aqui, o STP passa a atuar apenas para prevenção de conexões erradas de cabeamento, o etherchannel criado entre os switches de acesso e a camada de distribuição passa a oferecer o balanceamento de tráfego entre os links e o uso de FHRP não é mais necessário. Tudo isso resulta em um tempo de convergência muito melhor se comparado ao modelo tradicional de design em L2.
Descrevendo o modelo de acesso em Layer 3
Uma alternativa para o modo tradicional de design com bloco de switches de distribuição é fazer com que os switches de acesso atuem em modo L3 (routed access). A camada de acesso para a distribuição tradicionalmente composta por switches operando em L2 é substituída por switches que operam em modo L3. Isso significa que a demarcação entre as camadas de L2/L3 é movida da distribuição para a camada de acesso. Neste cenário não há necessidade de uso de FHRP.
Nesse modelo, o switch de acesso atua como o default gateway e cada switch participa do domínio de roteamento. O roteamento, se configurado corretamente, oferece ótimos resultados de balanceamento de carga e tempos de convergência.
No design de layer 3, o default gateway e o root bridge para as VLANs é simplesmente movido da camada de distribuição para o switch de acesso. O endereçamento IP de todos os end points permanece o mesmo, assim como o default gateway. VLANs e as configurações de portas dos switches de acesso configurações de interface de roteamento, access-lists, ip helper e qualquer outra configuração para cada VLAN permanece a mesma, Entretanto, as interfaces SVI agora são definidas nos switches de acesso ao invés de serem configuradas nos switches de distribuição.
Designs comuns de interconexão entre acesso e distribuição
Vamos explorar alguns modelos de design de interconexão entre a camada de acesso e a camada de distribuição e vamos entender como cada uma funciona.
Design Layer 2 Loop: Utiliza switches em layer 2 na camada de acesso até a conexão com os switches de distribuição. Este modelo necessita do uso do STP para evitar loops na rede o que acaba por inutilizar um dos uplinks do acesso até a distribuição. Em uma situação de falha do uplink, o tempo de convergência irá depender de como o STP e o FHRP estarão configurados.
Design Layer 2 Loop Free: Utiliza switches em layer 2 no acesso e layer 3 na interconexão entre os switches de distribuição. Não oferece um cenário de loop de camada 2 entre os switches de acesso e distribuição. Neste modelo, o tempo de convergência em caso de falha de um dos links depende dos tempo de convergência do FHRP.
Design StackWise virtual: Neste modelo, com o uso do StackWise e etherchannel, o STP reconhece o caminho do switch de acesso ao distribuição como um único link lógico. O STP é somente utilizados nas portas de acesso em que os dispositivos de usuários serão conectados, a fim de evitar que um usuário crie algum loop na rede. Se um dos uplinks falhar, o encaminhamento do tráfego se dará sem maiores problemas e sem a necessidade de reconvergência da rede.
Design Layer 3 routed access: Utiliza roteamento na camada de acesso e distribuição (inclusive na interconexão entre os switches de distribuição). Não há necessidade de utilização de STP, com exceção do uso nas portas de acesso aonde os equipamentos dos clientes serão conectados. O tempo de reconvergência depende exclusivamente do tempo de convergência do protocolo de roteamento utilizado.
Comparação dos tempos de convergência entre rede layer 2 e layer 3
Esse talvez seja o aprimoramento mais significante quando comparamos os tempos de convergência entre uma rede com a camada de acesso operando em L2 e uma rede operando no modo routed access, com o acesso em L3. Em uma rede layer 2 tradicional, o tempo de convergência do STP pode variar entre 800-900 msec, comparado com o modelo routed access, esse tempo é reduzido para menos de 200msec.
Aqui vale destacar que cada ambiente terá suas particularidades, estes valores são apenas referências de comparação entre um modelo de design L2 e outro em L3 Os tempos de convergência não necessariamente serão esses.
Modelo de acesso em L2 ou L3, qual a melhor escolha?
Qual design é melhor levando-se em consideração tudo o que foi apresentado até então?
O resultado final de qual design escolher é uma decisão de projeto baseado em vários fatores, não é possível dizer qual modelo é melhor sem conhecer os requisitos do ambiente e as necessidades do cliente, qual o budget disponível e etc. Operar em uma rede no modelo routed access trás vantagens em relação ao tempo de convergência, porém a mesma trás desvantagens com relação ao nível de conhecimento técnico necessário para mantê-la.
Já uma rede tradicional operando em L2 em um primeiro momento pode ser mais fácil de gerenciar, mas a mesma apresenta um tempo de convergência maior, para se ter um tempo de convergência próximo aos da rede routed access são necessários vários ajustes no STP e nos tempos do FHRP.
Com isso encerro essa primeira parte dessa série de artigos sobre design Enterprise Campus LAN. Na segunda parte falaremos especificamente sobre o design em Layer 2 e na parte 3 falaremos sobre o design em Layer 3.