Nessa série de artigos divididos em três partes, falaremos sobre design de uma rede Enterprise Campus LAN, a importância de criar um design eficiente e confiável para operação da rede local. Abordaremos os conceitos de uma rede tradicional em layer 2 e a diferença para o design routed access puramente em layer 3.
Introdução
Switches de camada 2 (ou switches L2) são frequentemente utilizados como meio de prover conectividade entre os clientes e a rede local. Toda segmentação do ambiente a nível de camada 2 (local area networks ou simplesmente LAN) são efetuadas nestes equipamentos.
Switches de camada 3 (switches L3) são basicamente roteadores com o “fast forwarding” feito via hardware. O encaminhamento de pacotes envolve a pesquisa de melhor rota, o decremento da contagem do TTL (time to live), o recalculo do checksum e o encaminhamento do quadro com o apropriado cabeçalho MAC para a correta porta de saída.
De forma implícita, acabamos assumindo que switches layer 3 também operam como switches Layer 2, mas isso nem sempre é verdade.
Vamos entender como combinar os switches Layer 2 e Layer 3 em um modelo de Enterprise Campus LAN.
Campus LAN – Endo-to-end VLANs ou Local VLANs
Dois dos principais modelos de design em Campus LAN são end-to-end VLANs e Local VLANs. Vamos entender como cada um desses dois modelos funcionam.
- End-to-End VLANs: Modelo em que todas as VLANs são distribuídas e disponíveis em todos os switches do Campus. Neste modelo, faz-se necessário o uso de ferramentas como o STP (spanning-tree) para prevenção de loops. Nesse modelo, os usuários tem acesso a suas respectivas VLANs independentemente de sua localização física no Campus. O termo end-to-end VLANs faz referência ao fato de uma única VLAN estar presente em múltiplos switches através da rede do Campus.
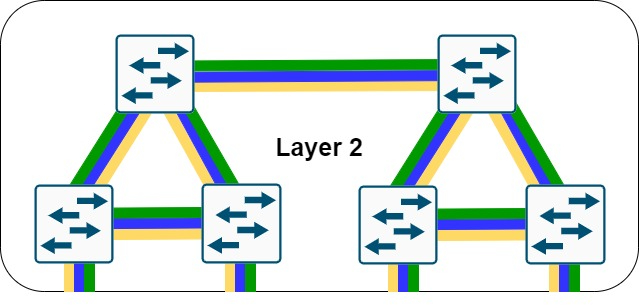
- Local VLANs: Neste modelo, os usuários são agrupados em VLANs dependendo de sua localização física, se um usuário move de um local para outro no campus, a VLAN que o mesmo irá utilizar será diferente. Neste caso, switches Layer 2 são utilizados para prover acesso ao usuário, já na camada de distribuição, o roteamento entre VLANs é efetuado para que o usuário consiga acessar os recursos necessários na rede.
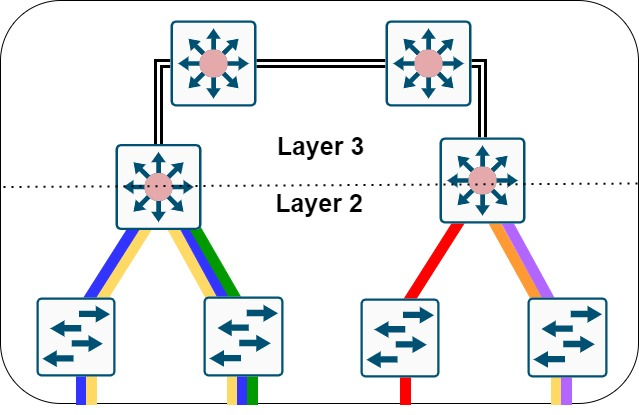
End-to-end VLANs e Local VLANs são dois tipos de design, durante a fase de planejamento você pode optar por utilizar um mix de ambos.
| End-to-End VLANs | Local VLANs |
| Pros: – Todas as VLANs estão disponíveis em todos os switches do Campus; – Mesmas políticas (QoS, segurança) são aplicadas aos usuários, independente de sua localização geográfica dentro do Campus. | Pros: – Modelo de design mais escalável; – Troubleshooting pode ser simplificado; – Caminhos redundantes podem ser facilmente criados. |
| Contras: – Todos os switches precisam estar configurados com todas as VLANs; – Mensagens de broadcast trafegam por todos os switches; – Troubleshoot pode ser um desafio neste ambiente. | Contras: – São necessários mais equipamentos com características de roteamento (switches L3). |
No modelo de end-to-end VLANs, você deve levar em consideração que todos os switches trafegam dados de todas as VLANs, mesmo que não haja um usuário conectado a uma determinada VLAN em algum switch do Campus. Por este motivo, efetuar troubleshooting neste tipo de ambiente pode ser um problema, pois, o tráfego de uma simples VLAN atravessa múltiplos switches no Campus.
Já no modelo de design de Local VLANs, as VLANs que são utilizadas para a camada de acesso não devem ser estendidas além do switch de distribuição. Este modelo de design pode mitigar muitos problemas, além de prover vários benefícios como:
- Determinar o caminho do tráfego: Este modelo provê de forma mais previsível o tráfego entre o switch L2 e o switch L3. Em uma eventual falha, a simplicidade do modelo permite facilita com que o problema seja isolado e rapidamente identificado.
- Caminhos redundantes: Com a implementação do STP (aqui considere as diferentes versões do STP como, RSTP, PVST, MST) é possível utilizar todos os links de interconexão entre o switch L2 e o switch L3 e utilizar caminhos redundantes.
- Menor ponto de falhas: Se a VLAN é local a um determinado bloco da rede e o número de usuários atrelados a essa VLAN é pequeno, uma eventual falha no layer 2 dessa VLAN acabará por impactar um número baixo de usuários.
- Design Escalável: Permite um design muito mais escalável, a incorporação de novos switches ou adição de novas VLANs no ambiente de forma muito mais simples.
O modelo tradicional de Layer 2
Em um design hierárquico tradicional, o bloco de distribuição usa uma combinação protocolos e serviços de camadas 2, 3 e 4 para prover convergência, escalabilidade, segurança e gerenciamento. Neste modelo, os switches de acesso são configurados como switches L2 e encaminham o tráfego através de uplinks com os switches de distribuição através de portas configuradas como trunks. Já os switches de distribuição são configurados para suportar o encaminhamento em L2 para os switches de acesso e também encaminhamentos em L3 para a camada superior, que é o core da rede.

Neste modelo tradicional de Layer 2, a demarcação entre as camadas de L2/L3 fica a cargo dos switches de distribuição. Eles atuam o default gateways para as redes (VLANs) que são criadas no ambiente e com o encaminhamento em L3 para a camada superior. Duas características deste modelo de design:
- 1º: É que não é possível alcançar de forma verdadeira o balanceamento de carga entre os links, já que o STP irá bloquear caminhos redundantes. Balanceamento de carga é efetuado através de manipulação do STP e FHRP (First Hop Redundancy Protocol), enviando o tráfego de diferentes VLANs em diferentes links, porém, manipulação manual do STP e FHRP não é uma forma verdadeira de efetuar balanceamento de carga.
- 2º: O tempo de convergência da rede pode ser alto. Implementações do STP como RSTP tornam o tempo de convergência da rede mais rápido, mas isso só é possível alcançar com um bom nível de design de roteamento hierárquico e ajustando-se os tempos de convergência do FHRP.
Modelo de layer L2 atualizado
Neste modelo, as VLANs ainda são terminadas nos switches de distribuição (os switches continuam atuando como default gateways). A diferença é que não há mais links bloqueados através do STP. O uso de features como StackWise virtual, presente em switches da séries Catalyst 9500 por exemplo, permite que que dois switches operem logicamente como um único equipamento.
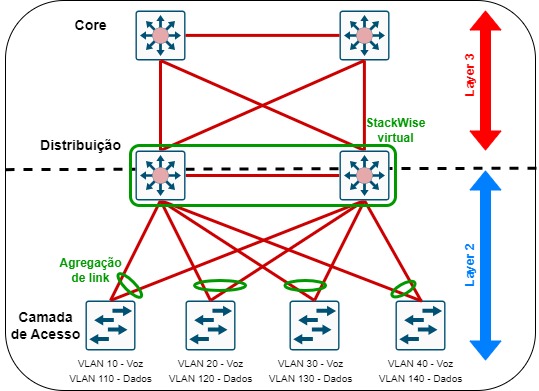
Aqui, o STP passa a atuar apenas para prevenção de conexões erradas de cabeamento, o etherchannel criado entre os switches de acesso e a camada de distribuição passa a oferecer o balanceamento de tráfego entre os links e o uso de FHRP não é mais necessário. Tudo isso resulta em um tempo de convergência muito melhor se comparado ao modelo tradicional de design em L2.
Descrevendo o modelo de acesso em Layer 3
Uma alternativa para o modo tradicional de design com bloco de switches de distribuição é fazer com que os switches de acesso atuem em modo L3 (routed access). A camada de acesso para a distribuição tradicionalmente composta por switches operando em L2 é substituída por switches que operam em modo L3. Isso significa que a demarcação entre as camadas de L2/L3 é movida da distribuição para a camada de acesso. Neste cenário não há necessidade de uso de FHRP.
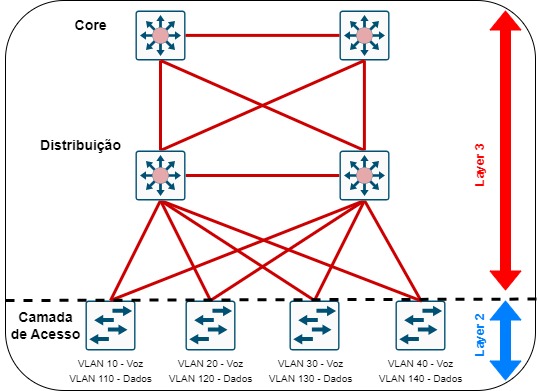
Nesse modelo, o switch de acesso atua como o default gateway e cada switch participa do domínio de roteamento. O roteamento, se configurado corretamente, oferece ótimos resultados de balanceamento de carga e tempos de convergência.
No design de layer 3, o default gateway e o root bridge para as VLANs é simplesmente movido da camada de distribuição para o switch de acesso. O endereçamento IP de todos os end points permanece o mesmo, assim como o default gateway. VLANs e as configurações de portas dos switches de acesso configurações de interface de roteamento, access-lists, ip helper e qualquer outra configuração para cada VLAN permanece a mesma, Entretanto, as interfaces SVI agora são definidas nos switches de acesso ao invés de serem configuradas nos switches de distribuição.
Designs comuns de interconexão entre acesso e distribuição
Vamos explorar alguns modelos de design de interconexão entre a camada de acesso e a camada de distribuição e vamos entender como cada uma funciona.

- Design Layer 2 Loop: Utiliza switches em layer 2 na camada de acesso até a conexão com os switches de distribuição. Este modelo necessita do uso do STP para evitar loops na rede o que acaba por inutilizar um dos uplinks do acesso até a distribuição. Em uma situação de falha do uplink, o tempo de convergência irá depender de como o STP e o FHRP estarão configurados.
- Design Layer 2 Loop Free: Utiliza switches em layer 2 no acesso e layer 3 na interconexão entre os switches de distribuição. Não oferece um cenário de loop de camada 2 entre os switches de acesso e distribuição. Neste modelo, o tempo de convergência em caso de falha de um dos links depende dos tempo de convergência do FHRP.
- Design StackWise virtual: Neste modelo, com o uso do StackWise e etherchannel, o STP reconhece o caminho do switch de acesso ao distribuição como um único link lógico. O STP é somente utilizados nas portas de acesso em que os dispositivos de usuários serão conectados, a fim de evitar que um usuário crie algum loop na rede. Se um dos uplinks falhar, o encaminhamento do tráfego se dará sem maiores problemas e sem a necessidade de reconvergência da rede.
- Design Layer 3 routed access: Utiliza roteamento na camada de acesso e distribuição (inclusive na interconexão entre os switches de distribuição). Não há necessidade de utilização de STP, com exceção do uso nas portas de acesso aonde os equipamentos dos clientes serão conectados. O tempo de reconvergência depende exclusivamente do tempo de convergência do protocolo de roteamento utilizado.
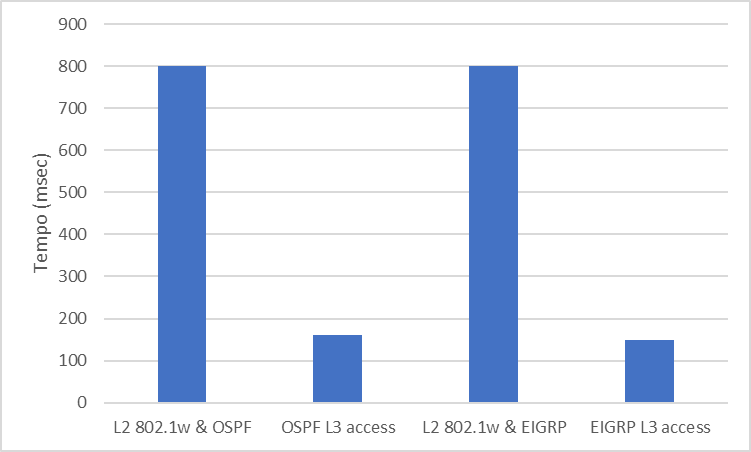
Comparação dos tempos de convergência entre rede layer 2 e layer 3
Esse talvez seja o aprimoramento mais significante quando comparamos os tempos de convergência entre uma rede com a camada de acesso operando em L2 e uma rede operando no modo routed access, com o acesso em L3. Em uma rede layer 2 tradicional, o tempo de convergência do STP pode variar entre 800-900 msec, comparado com o modelo routed access, esse tempo é reduzido para menos de 200msec.
Aqui vale destacar que cada ambiente terá suas particularidades, estes valores são apenas referências de comparação entre um modelo de design L2 e outro em L3 Os tempos de convergência não necessariamente serão esses.
Modelo de acesso em L2 ou L3, qual a melhor escolha?
Qual design é melhor levando-se em consideração tudo o que foi apresentado até então?

O resultado final de qual design escolher é uma decisão de projeto baseado em vários fatores, não é possível dizer qual modelo é melhor sem conhecer os requisitos do ambiente e as necessidades do cliente, qual o budget disponível e etc. Operar em uma rede no modelo routed access trás vantagens em relação ao tempo de convergência, porém a mesma trás desvantagens com relação ao nível de conhecimento técnico necessário para mantê-la.
Já uma rede tradicional operando em L2 em um primeiro momento pode ser mais fácil de gerenciar, mas a mesma apresenta um tempo de convergência maior, para se ter um tempo de convergência próximo aos da rede routed access são necessários vários ajustes no STP e nos tempos do FHRP.
Com isso encerro essa primeira parte dessa série de artigos sobre design Enterprise Campus LAN. Na segunda parte falaremos especificamente sobre o design em Layer 2 e na parte 3 falaremos sobre o design em Layer 3.
Bons estudos e até a próxima.